Series: The Sequentia Lectures: Unlocking the Math of AI
Part 6: Advanced Architectures & Concepts
Lecture 48: Pooling Layers: Summarizing Information to See the Big Picture
In our last two lectures, we’ve seen how a Convolutional Neural Network (CNN) uses filters to scan an image and create feature maps. Each feature map is a grid that highlights where a specific low-level feature—like a vertical edge, a horizontal line, or a particular texture—appears in the input image.
This is a powerful process, but it leaves us with a lot of data. If we start with a 256×256 image and apply 64 different filters, we end up with 64 different 256×256 feature maps! This is a huge amount of information, and it’s still very sensitive to the exact location of features. If an edge moves by just one pixel, the feature map will change.
How does the network move from this noisy, high-resolution detail to a more robust, “big picture” understanding of the image? It uses a clever down-sampling technique called pooling.
What is a Pooling Layer?
A pooling layer is a step in a CNN that systematically reduces the spatial size of the feature maps. Its job is to summarize the features in a local neighborhood, keeping only the most essential information and discarding redundant details.
The most common type of pooling is Max Pooling.
How Max Pooling Works: The “Best in the Neighborhood”
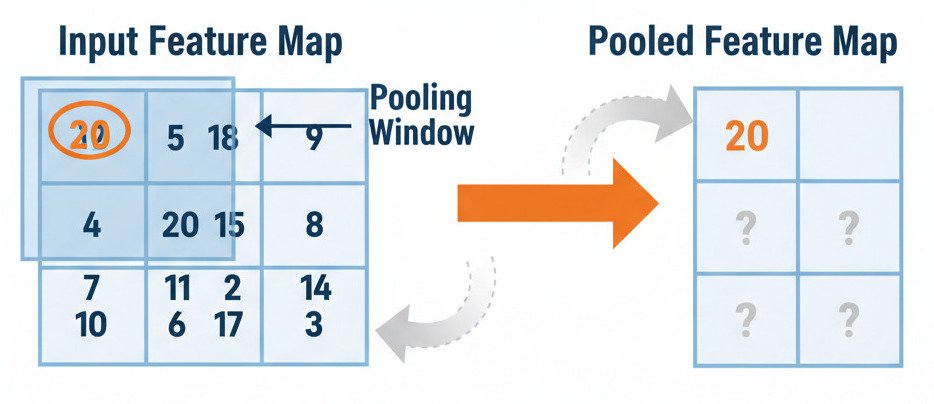
The Max Pooling operation is even simpler than a convolution. It also uses a sliding window, typically a small 2×2 square, that moves across the feature map.
- Placement: The 2×2 window is placed over the top-left corner of the feature map.
- Find the Maximum: It looks at the four numbers inside its window and finds the single largest (maximum) value.
- Output: This single maximum value becomes the top-left pixel of the new, smaller “pooled” feature map.
- Slide: The window then slides to the right (usually with a “stride” of 2, so the windows don’t overlap) and repeats the process.
By taking a 2×2 window with a stride of 2, the Max Pooling layer effectively shrinks the feature map to half its original height and width, reducing the total number of data points by 75%!
Why is Pooling So Important?
This aggressive summarization provides two crucial benefits:
- Computational Efficiency: By dramatically reducing the size of the data, pooling makes subsequent layers in the network much faster and more memory-efficient. The number of parameters needed in later layers is significantly reduced, which helps to speed up training and prevent overfitting.
- Translation Invariance (Robustness): This is the more subtle and powerful benefit. Max Pooling makes the model’s representation more robust to small shifts in the position of features.
- The Intuition: The max pooling operation is essentially asking, “Is this feature (e.g., a vertical edge) present somewhere in this 2×2 neighborhood?” It doesn’t care about the exact pixel location of the feature, only that its “strongest signal” (the max value) is captured.
- The Effect: If the vertical edge in the original image shifts by one pixel, the activation in the original feature map might also shift. But as long as that maximum activation value remains within the same 2×2 pooling window, the output of the pooling layer will be exactly the same.
This gives the network a degree of “local translation invariance,” meaning it learns to care more about whether a feature exists in a general area, rather than precisely where it exists. This is critical for building a robust object detector that can recognize a cat whether its eye is in pixel (50, 52) or (51, 53).
The CNN Architecture: Convolution and Pooling Pairs
The typical architecture of a CNN involves a repeating sequence of these layers:
Input -> [Convolution -> Activation(ReLU)] -> [Pooling] -> [Convolution -> Activation(ReLU)] -> [Pooling] -> … -> Fully Connected Layers for Classification
- The Convolutional layers act as feature detectors, creating detailed maps of where specific patterns are found.
- The Pooling layers act as summarizers, reducing the size of these maps and making the feature representation more robust and abstract.
As data passes through this sequence, it is progressively transformed from a raw grid of pixels into a high-level, spatially compact representation of “what” is in the image, rather than “where” every single detail is. Pooling is the essential step that allows the network to see the forest, not just the individual trees.
