Series: The Sequentia Lectures: Unlocking the Math of AI
Part 5: Core Machine Learning in Action
Lecture 42: Overfitting vs. Underfitting: The Art of Generalizing, Not Memorizing
We’ve learned how to build and train powerful machine learning models. We have a clear objective: to minimize our cost function on the training data. But this leads to a subtle and dangerous trap. Is a low error score on the data we’ve already seen really our ultimate goal?
No. Our ultimate goal is to create a model that performs well on new, unseen data. The ability to do this is called generalization. And the two most common ways a model can fail to generalize are underfitting and overfitting.
To understand this, let’s use the analogy of a student studying for an important exam.
Underfitting: The Student Who Didn’t Study
Imagine a student who barely glances at the textbook. They learn only the most basic, high-level concepts and ignore all the details.
- On practice questions (training data): They perform poorly. Their understanding is too simplistic to capture the nuances of the material.
- On the final exam (new data): They also perform poorly, for the same reason.
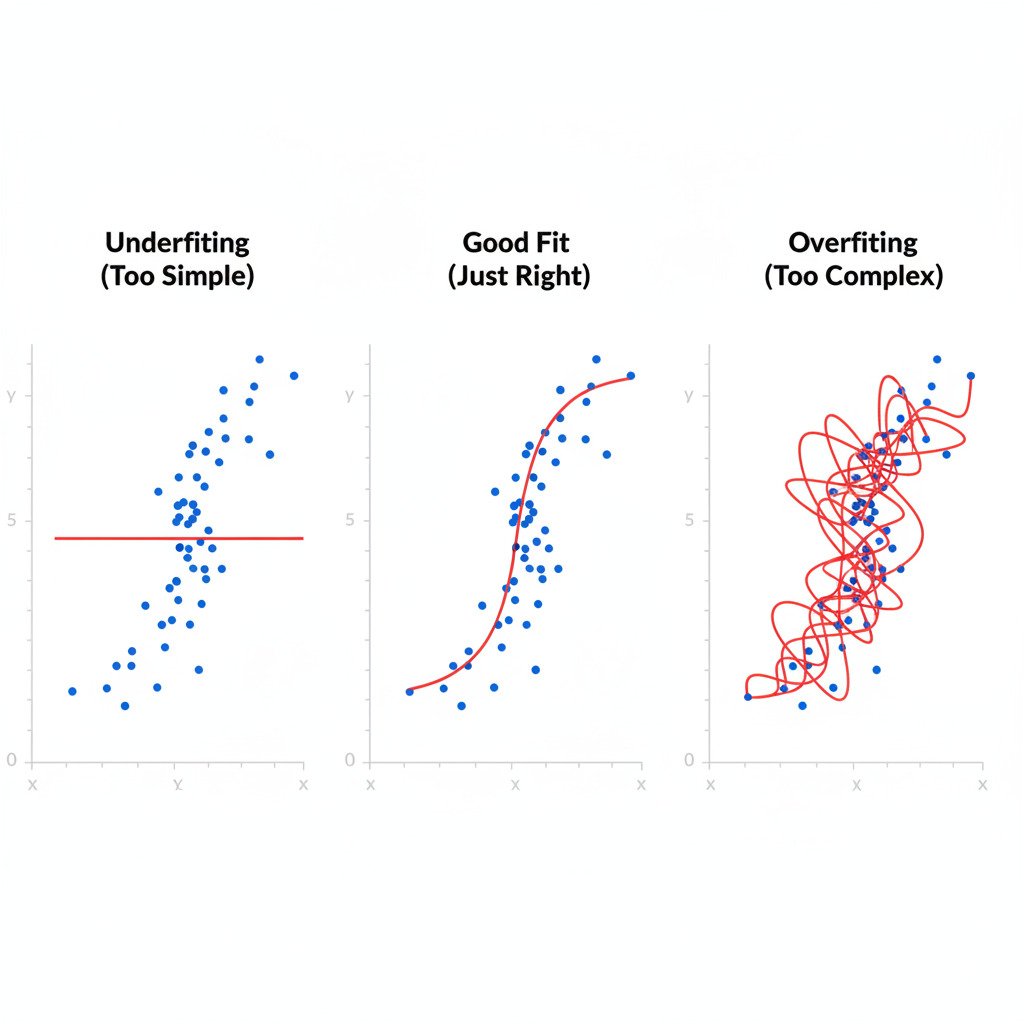
This is underfitting. It happens when a model is too simple to capture the underlying patterns in the data.
- The Model: A linear regression line trying to fit a complex, curvy dataset. A very shallow neural network trying to classify complex images.
- The Symptom: The model has high error on both the training data and the test data. It’s not learning the signal and is performing badly everywhere. It has “high bias.”
An underfit model is not a good model, but at least it’s honest about its poor performance. The solution is usually to use a more complex model (e.g., add more layers or neurons to the network).
Overfitting: The Student Who Memorized the Textbook
Now, imagine a different student. This student is incredibly diligent but takes the wrong approach. They don’t try to understand the concepts; they memorize every single word and punctuation mark of the practice questions and their answers.
- On practice questions (training data): They get a perfect score! They’ve seen these exact questions before and have memorized the exact answers.
- On the final exam (new data): They fail miserably. The exam questions are slightly different, phrased in a new way, or cover the same concepts but with new examples. Because the student only memorized the specifics and not the underlying principles, they are unable to adapt.
This is overfitting. It happens when a model is too complex and, instead of learning the true, underlying signal in the data, it starts to memorize the random noise and quirks of the specific training set.
- The Model: A very deep, complex neural network with millions of parameters trained on a small dataset. An overly flexible curve that wiggles to pass through every single data point perfectly.
- The Symptom: The model has extremely low error on the training data but high error on the test data. It looks like a genius on the data it has seen, but it fails to generalize to new, unseen data. It has “high variance.”
Overfitting is a far more dangerous and deceptive problem than underfitting because the model looks like it’s performing perfectly during training.
Generalization: The Student Who Understands the Concepts
The ideal student is one who studies the practice questions to understand the underlying principles and concepts. They don’t just memorize answers; they learn the “why.”
- On practice questions (training data): They perform very well, though maybe not 100% perfect (they might not bother memorizing a typo in the textbook).
- On the final exam (new data): They also perform very well, because they can apply their understanding of the core concepts to these new, slightly different questions.
This is generalization. It’s the “sweet spot” between underfitting and overfitting. The model is complex enough to capture the true signal in the data, but not so complex that it starts memorizing the noise.
- The Symptom: The model has low error on the training data and low error on the test data. The performance on seen and unseen data is very similar.
Finding the Sweet Spot
The central art of machine learning is finding this balance. We use a variety of techniques to combat overfitting, collectively known as regularization. These techniques (like adding penalties for large weights, or randomly “dropping out” neurons during training) are like telling the student: “Don’t just memorize; focus on the simplest, most robust explanation for the data.”
The battle between overfitting and underfitting is a constant tug-of-war. Our goal is never to build a perfect memorizer, but a flexible and robust learner that can take its knowledge and apply it to the new challenges the world will throw at it.
