Series: The Sequentia Lectures: Unlocking the Math of AI
Part 5: Core Machine Learning in Action
Lecture 39: Activation Functions: The “Switches” That Give Neurons Power (ReLU)
In our last lecture, we met the Perceptron, the single artificial neuron. Its core operation was a weighted sum of inputs followed by a decision-making step. We’ve also learned that in a modern neural network, layers are essentially a series of matrix transformations.
But this presents a major problem. If we simply stack a series of purely linear transformations (like matrix multiplications) on top of each other, the end result is just another, more complex linear transformation. A network of purely linear neurons, no matter how deep, can only ever learn linear patterns. It would be great at fitting straight lines to data, but completely helpless at modeling the complex, curvy, non-linear relationships that define the real world.
So, how do neural networks learn to recognize complex shapes in images or understand the nuanced grammar of language? The secret lies in a small but crucial component added to the end of each neuron: the Activation Function.
What is an Activation Function?
An activation function is a non-linear “switch” or “filter” that is applied to the output of a neuron’s weighted sum. It takes the result of (weighted sum + bias) and decides what the neuron’s final output, or “activation,” should be.
In the original Perceptron, this was a simple, harsh step function: if the input was positive, output 1; otherwise, output 0. In Logistic Regression, we used the smooth, S-shaped sigmoid function to squash the output into a probability between 0 and 1.
These functions introduce a vital non-linearity into the system. It’s this non-linearity, applied at every neuron, that gives the network its immense power. By combining many simple non-linear units, a neural network can approximate any arbitrarily complex, curvy function.
The Modern King of Activation: ReLU
For many years, functions like Sigmoid and its cousin, Tanh, were the standard activation functions. But in modern deep learning, the undisputed king is a function that is almost comically simple: the Rectified Linear Unit, or ReLU.
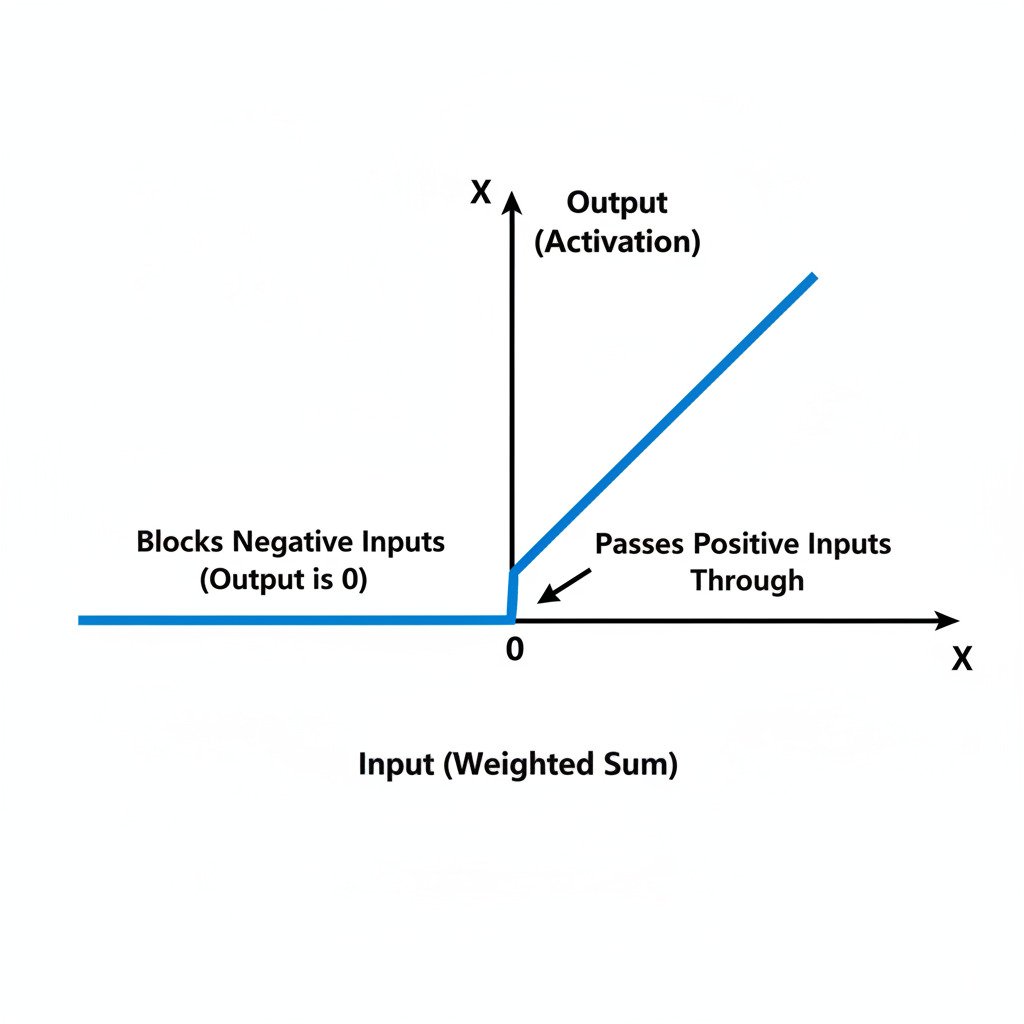
The rule for ReLU is incredibly straightforward:
- If the input is positive, the output is the input itself.
- If the input is negative, the output is zero.
That’s it. It’s like a gatekeeper that lets all positive signals pass through unchanged but completely blocks all negative signals. Mathematically, f(x) = max(0, x).
Why is ReLU so effective?
Despite its simplicity, ReLU (and its variants) solved several major problems that plagued older activation functions:
- Computational Efficiency: The max(0, x) operation is extremely fast for a computer to calculate, much faster than the complex exponents in the Sigmoid function. This makes training deep networks significantly quicker.
- Solves the “Vanishing Gradient” Problem: In very deep networks, using Sigmoid could cause the error signal (the gradient) to shrink to almost zero as it was passed backwards (backpropagated) through many layers. This meant the early layers of the network would stop learning. Because ReLU doesn’t “squash” positive values, it allows the gradient to flow much more effectively through the network, enabling the training of much deeper architectures.
- Sparsity: Because ReLU outputs zero for all negative inputs, it means that at any given time, a portion of the neurons in the network are “inactive” or “off.” This “sparsity” can make the network more efficient and can be seen as a form of specialization, where different neurons learn to respond to different features.
The Power of Stacking Simple Switches
It’s difficult to overstate the importance of these simple non-linear switches. Imagine you’re building with LEGOs. If you only have straight, flat pieces (linear functions), you can only build flat walls and straight lines.
But the moment you get a simple hinge piece (a non-linear activation function), you can suddenly create angles, curves, and incredibly complex 3D structures.
A deep neural network is just this principle on a massive scale. Each layer learns a linear transformation (the matrix multiplication), and then the ReLU activation function acts as a “hinge,” bending and folding the data landscape. By stacking hundreds of these “transform-and-bend” layers, the network can twist and shape the initial data landscape into a form where the patterns (like the “cat” cluster vs. the “dog” cluster) are easily separable.
The humble activation function is the component that elevates a neural network from a simple linear model into a universal function approximator, capable of learning the breathtaking complexity of the real world.
