Series: The Sequentia Lectures: Unlocking the Math of AI
Part 4: The AI Toolkit: Probability & Statistics
Lecture 33: Information Theory 101: What is Entropy and “Surprise”?
In our journey so far, we’ve used words like “uncertainty,” “information,” and “surprise” in a casual way. But what if we could measure them? What if there was a mathematical way to quantify the amount of uncertainty in a system or the amount of “surprise” in a new piece of information?
This is the central question of Information Theory, a field pioneered by the brilliant mathematician Claude Shannon. The core concept he developed to measure this is called entropy.
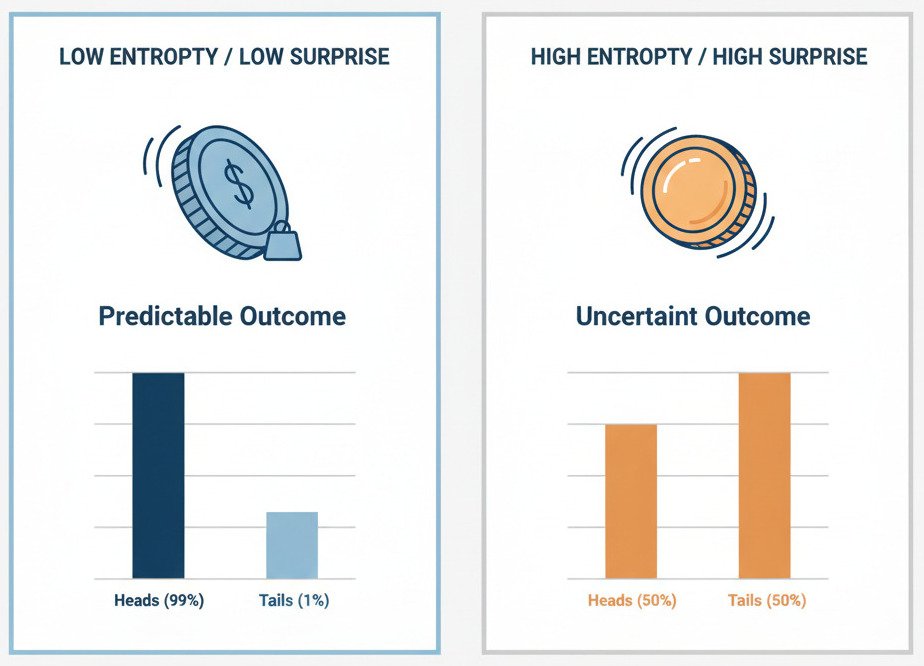
Entropy: A Measure of Uncertainty or “Surprise”
In the context of information theory, entropy is a measure of the average uncertainty or “messiness” of a random variable’s possible outcomes.
Think of it this way:
- Low Entropy: The outcome is very predictable. There is little uncertainty or surprise.
- High Entropy: The outcome is very unpredictable. There is high uncertainty, and any outcome would be more surprising.
Let’s consider two different coins:
- A Biased Coin: This coin is weighted to land on Heads 99% of the time. Before you flip it, you’re already very certain about the outcome. There’s very little “surprise” when it does, in fact, land on Heads. This system has low entropy.
- A Fair Coin: This coin has a 50/50 chance of landing on Heads or Tails. Before you flip it, you are in a state of maximum uncertainty. You have no idea which way it will land. The outcome is highly “surprising.” This system has high entropy.
The mathematical formula for entropy (which involves logarithms of probabilities) is designed to peak when all outcomes are equally likely (like the fair coin) and be at its lowest when one outcome is a near certainty (like the biased coin).
Information as a Reduction in Uncertainty
Information theory provides a beautiful definition of “information”: information is a reduction in entropy.
When you receive a new piece of data that makes you less uncertain about the outcome, you have gained information. If I tell you “it’s sunny outside,” your uncertainty about whether you need an umbrella decreases—you’ve received information.
From “Surprise” to Cost Functions in AI
This concept of “surprise” is not just a neat analogy; it’s the foundation for some of the most important cost functions in machine learning, especially for classification problems.
One such cost function is called Cross-Entropy. While the math can be a bit deep, the intuition is simple. Cross-entropy measures the “surprise” a machine learning model feels when it sees the true answer.
Let’s imagine our cat vs. dog classifier:
- The True Answer: The image is a Cat. (In probability terms, this is a distribution: [Cat: 1, Dog: 0]).
- Scenario 1 (Good Model): Our model is confident and predicts: [Cat: 0.95, Dog: 0.05]. This prediction is very close to the true answer. When the model is “shown” that the answer was indeed “Cat,” it’s not very surprised. The cross-entropy (the cost) will be very low.
- Scenario 2 (Bad Model): Our model is very wrong and confidently predicts: [Cat: 0.1, Dog: 0.9]. This prediction is very far from the true answer. When the model is “shown” that the answer was actually “Cat,” it is extremely “surprised”! The cross-entropy (the cost) will be very high.
The goal of training a classification model using a cross-entropy loss function is, therefore, to minimize its average surprise across the entire dataset. The model adjusts its weights via Gradient Descent to make predictions that are as close as possible to the true outcomes, thereby reducing its “surprise” when it sees the correct labels.
By framing “error” as “surprise,” information theory gives us a powerful and elegant way to train our models. The AI learns by constantly trying to make the world less surprising, which in turn means its internal model of the world is becoming more and more accurate.
Entropy, therefore, is more than just a measure of messiness. It’s a fundamental concept that allows us to quantify uncertainty, define information, and build cost functions that drive our AI models to learn.
