Series: The Sequentia Lectures: Unlocking the Math of AI
Part 6: Advanced Architectures & Concepts
Lecture 52: Embeddings: Turning Words into Vectors for AI to Understand
We’ve talked a lot about how AI models process numbers, but how do they handle the most human of data types: language? A computer doesn’t understand the meaning of “cat,” “democracy,” or “love.” So, how can it possibly translate sentences, analyze sentiment, or answer questions?
The answer lies in a revolutionary technique that forms the foundation of modern Natural Language Processing (NLP): Word Embeddings.
The Problem: Words are not Numbers
The simplest way to represent a word numerically is to assign it a unique ID, like in a dictionary: “a”: 1, “apple”: 2, …, “zebra”: 26000. This is called integer encoding. A slightly more complex method is one-hot encoding, where each word is a giant vector of all zeros except for a single 1 at the position of its ID.
But these methods have a huge flaw: they contain no information about meaning. The number 2 (“apple”) is no more related to the number 150 (“fruit”) than it is to 25987 (“rocket”). These representations are sparse, inefficient, and, most importantly, semantically meaningless. The model has to learn every relationship from scratch.
The Solution: Representing Meaning as a Location
Word embeddings solve this by mapping each word in a vocabulary not to a single number, but to a dense vector of real numbers, typically a few hundred dimensions long.
“king” -> [0.98, -0.12, 0.45, 0.67, …, -0.81]
“queen” -> [0.95, -0.15, 0.43, 0.02, …, -0.79]
“apple” -> [0.21, 0.55, -0.34, 0.11, …, 0.09]
This vector is the “embedding” of the word. It’s a coordinate, an address that places the word as a point in a high-dimensional “meaning space.”
The magic of this space is that it is structured according to the words’ semantic relationships.
- Words with similar meanings will be located close to each other. The vector for “cat” will be near the vector for “kitten.”
- Words with opposite meanings might be far apart.
- Incredibly, the relationships between words are also captured as mathematical operations on their vectors.
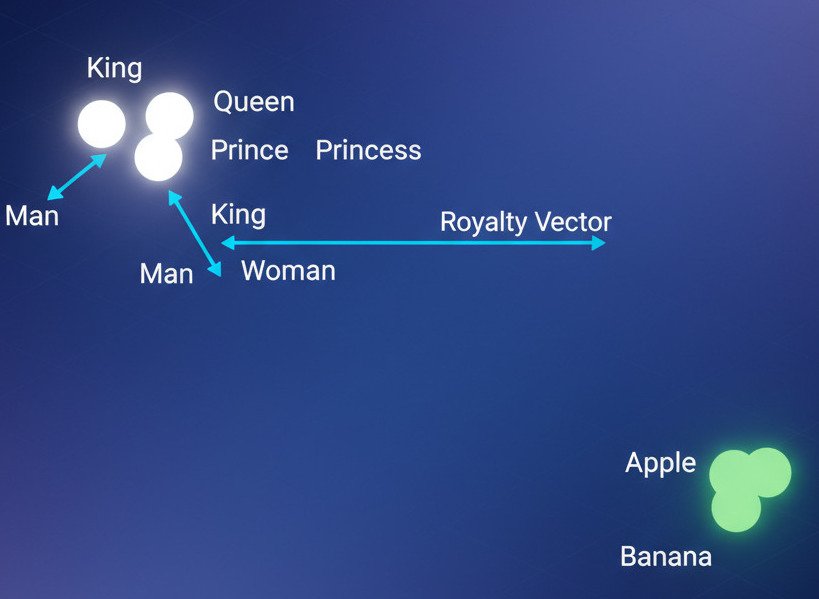
The Famous “King – Man + Woman = Queen” Analogy
The most famous example of this semantic arithmetic is the vector equation:
vector(“king”) – vector(“man”) + vector(“woman”) ≈ vector(“queen”)
This means that the “direction” in the vector space that goes from “man” to “king” (the concept of royalty or leadership applied to a male) is roughly the same as the direction that goes from “woman” to “queen.” Similarly, vector(“Paris”) – vector(“France”) + vector(“Germany”) would result in a vector very close to vector(“Berlin”).
The embedding has learned these complex analogies and relationships purely from observing how words are used in context in a massive amount of text.
How are Embeddings Learned?
Embeddings are not manually created; they are learned by a neural network. Models like Word2Vec and GloVe were pioneers in this.
The core principle is the distributional hypothesis: “You shall know a word by the company it keeps.”
The model is trained on a massive corpus of text (like all of Wikipedia). It slides a “window” across the text and learns to predict a word based on its neighboring words (or vice-versa). By performing this task billions of times, the model is forced to adjust its internal word vectors so that words that frequently appear in similar contexts (like “cat” and “kitten”) end up with similar vector representations.
The embedding layer in a modern neural network is often the very first layer. It acts as a “lookup table.” When the model receives a word (as an ID), it looks up its corresponding dense vector in the embedding table and feeds this meaningful, numerical representation into the rest of the network.
The Foundation of Modern NLP
Word embeddings were a monumental breakthrough. They transformed language from a series of arbitrary symbols into a rich, geometric landscape where concepts have a location and relationships are mathematical.
This is the technology that powers:
- Sophisticated search engines that understand query meaning.
- Machine translation services that preserve context.
- Sentiment analysis tools that grasp the nuance of language.
- Large Language Models (LLMs) like GPT, which are built upon even more advanced, context-aware versions of this core idea.
By turning words into vectors, embeddings give AI the ability to finally start understanding the rich tapestry of human language.
