Series: The Sequentia Lectures: Unlocking the Math of AI
Part 5: Core Machine Learning in Action
Lecture 43: Regularization (L1 & L2): The Mathematical Penalty for “Thinking Too Hard”
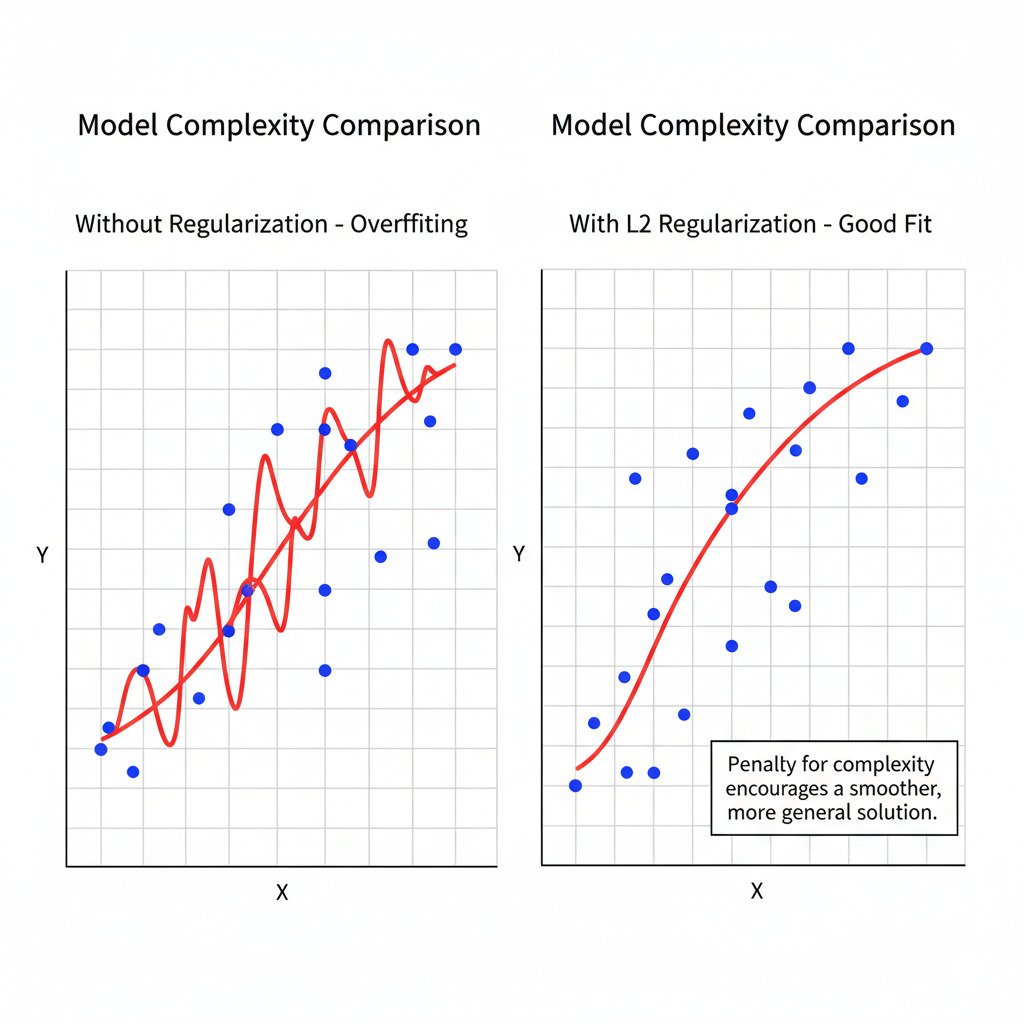
In our last lecture, we met the dangerous problem of overfitting. This is when our model becomes too complex, like a student who memorizes the textbook instead of understanding the concepts. It performs perfectly on the training data it has seen, but fails to generalize to new, unseen problems.
So, how do we actively prevent our models from “thinking too hard” and memorizing the noise in our data? How do we encourage them to find the simplest, most robust patterns? The primary technique for this is called Regularization.
The Core Idea: A Penalty for Complexity
Regularization works by adding a penalty term to our model’s cost function. Remember, the cost function is what we are trying to minimize during training. Our original cost function was focused purely on minimizing the prediction error.
Original Cost = Error (e.g., Mean Squared Error)
The new, regularized cost function has two parts:
New Cost = Error + Penalty
This penalty term is calculated based on the size of the model’s parameters (the weights). The larger and more extreme the weights in our model, the bigger the penalty becomes.
Now, when our Gradient Descent algorithm works to minimize this new cost function, it has to balance two competing goals:
- Minimize the error: Fit the data well.
- Minimize the penalty: Keep the model’s weights small and simple.
This trade-off forces the model to find a solution that not only explains the data but does so in the simplest way possible. It’s like telling the memorizing student, “I’ll grade you not just on getting the right answers, but also on the simplicity and elegance of your explanation.”
The Two Flavors of Regularization: L2 and L1
There are two dominant types of regularization, and they differ only in how they calculate the penalty from the weights.
L2 Regularization (Ridge Regression / Weight Decay):
- The Penalty: The L2 penalty is the sum of the squares of all the weights in the model, multiplied by a small regularization parameter (lambda, λ).
L2 Penalty = λ * (w₁² + w₂² + w₃² + …) - The Intuition: Squaring the weights means that very large weights get a huge penalty, while small weights get a tiny one. L2 regularization acts like a gentle but persistent force that encourages all weights to be small and distributed. It dislikes “spiky,” outlier weights and prefers a model where many features contribute a small amount.
- The Effect: This results in smoother, less complex model functions (like a less “wiggly” curve) that are less likely to overfit. It’s the most common type of regularization.
L1 Regularization (Lasso Regression):
- The Penalty: The L1 penalty is the sum of the absolute values of all the weights, multiplied by the regularization parameter λ.
L1 Penalty = λ * (|w₁| + |w₂| + |w₃| + …) - The Intuition: The L1 penalty is different. As it pushes weights to be smaller, it has a tendency to push some of them all the way to zero.
- The Effect: L1 regularization acts as a form of automatic feature selection. If a feature is not very useful, the model will learn to set its weight to exactly zero, effectively ignoring it. This results in a “sparse” model, where only the most important features have non-zero weights. This can be very useful for understanding which features are the most predictive in your data.
Choosing a Regularization Strength (λ)
The regularization parameter, lambda λ, is another “hyperparameter” that we, the data scientists, must choose. It controls the strength of the penalty.
- If λ = 0, there is no penalty, and we’re back to the original, non-regularized cost function.
- If λ is very large, the penalty for large weights is so severe that the model will be forced to have tiny weights, potentially leading to underfitting (being too simple).
Finding the right value for λ is part of the art of “hyperparameter tuning,” balancing the need to fit the data against the need for simplicity.
By adding a simple mathematical penalty for complexity to our cost function, regularization provides an elegant and powerful way to guide our learning algorithms. It encourages our models to be not just accurate, but also robust and generalizable, ensuring they learn the true signal from the data, not just memorize its noise.
