Series: The Sequentia Lectures: Unlocking the Math of AI
Part 4: The AI Toolkit: Probability & Statistics
Lecture 31: The Law of Large Numbers: Why More Data is Usually Better
In the world of AI and data science, you’ll constantly hear a single, unifying mantra: “More data is better.” Why is this the case? Is it just a guess, or is there a fundamental mathematical reason for it?
The answer lies in a simple but profound statistical principle called the Law of Large Numbers (LLN). This law provides the mathematical bedrock for our confidence in data, and it’s the reason why training AI models on massive datasets generally leads to more reliable and accurate performance.
The Core Idea: Convergence to the Truth
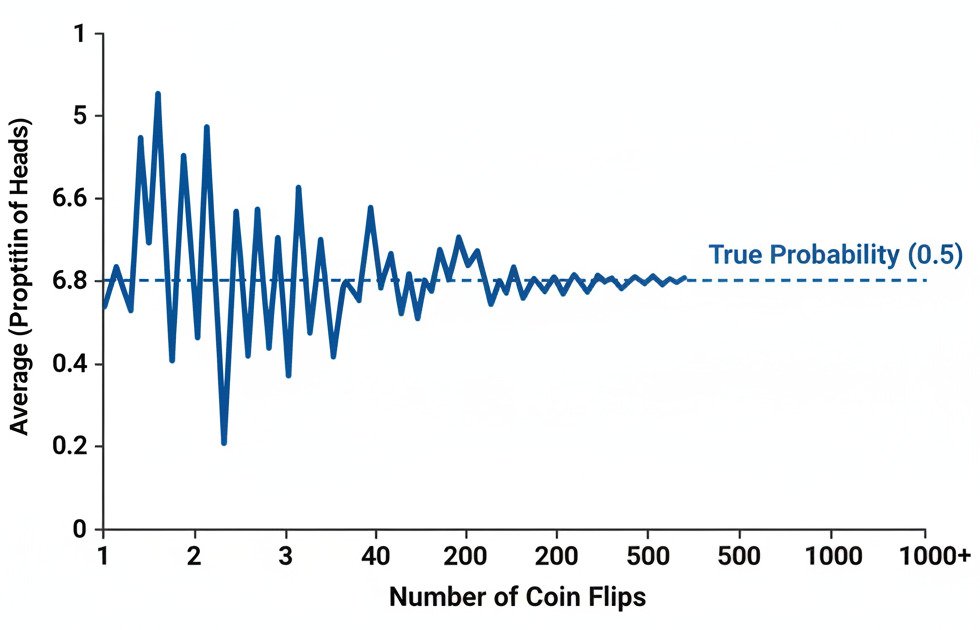
The Law of Large Numbers states that as the size of your sample from a random process increases, the average of your sample results will get closer and closer to the “true” expected value (the theoretical average) of the process.
In simpler terms: The more times you try something, the more your average outcome will reflect the true underlying probability.
An Intuitive Example: Flipping a Coin
Imagine you’re flipping a fair coin. The “true” expected value or probability of getting heads is 0.5 (or 50%).
- Small Sample (10 Flips): If you flip the coin just 10 times, you could easily get an unusual result due to random chance. You might get 7 heads (an average of 0.7) or 3 heads (an average of 0.3). Your small sample doesn’t give you a very reliable estimate of the true probability. Your result is “noisy.”
- Large Sample (10,000 Flips): If you flip the coin 10,000 times, the results of random chance start to even out. It’s extremely unlikely you’ll get 7,000 heads. Instead, your result will be very, very close to 5,000 heads, making your sample average incredibly close to the true 0.5.
The Law of Large Numbers guarantees this convergence. As the number of trials (or samples) approaches infinity, the sample average will converge to the true average.
From Coin Flips to AI Models
This principle is directly applicable to how we train and evaluate AI models.
1. Training the Model:
When we train a model, we’re trying to learn the “true” underlying patterns (y = f(x)) that govern our data. The training dataset we use is just a sample of all the possible data in the universe.
- Small Dataset: If we train a cat vs. dog classifier on only 100 images, it might learn spurious, accidental patterns. Maybe, by chance, most of the cat pictures in this small set happen to be indoors, and most dog pictures are outdoors. The model might incorrectly learn the rule “indoors = cat” and “outdoors = dog.” Its understanding is based on a noisy, unrepresentative sample.
- Large Dataset: If we train on a million images of cats and dogs in all sorts of environments (indoors, outdoors, day, night, different breeds), the random noise and accidental correlations will average out. The model is forced to learn the true, consistent patterns that actually define a cat versus a dog. The larger dataset provides a more accurate approximation of the “true” distribution of cat and dog images in the world.
2. Evaluating the Model:
The LLN is also why we need a large, separate “test set” to confidently evaluate our model’s performance. If we only test our model on 10 new images and it gets 9 right, we can’t be very confident in its 90% accuracy. That result could just be luck. If we test it on 10,000 new images and it gets 9,000 right, the Law of Large Numbers tells us that this 90% accuracy is a much more reliable estimate of its true performance on any new data it might encounter.
The Takeaway: Trust in Volume
The Law of Large Numbers is a comforting principle. It assures us that with enough data, the chaotic and random nature of the world can be tamed, and the true underlying patterns can emerge. It’s the mathematical justification for the immense data appetites of modern AI.
While the quality of data is always paramount, the LLN tells us that, all else being equal, quantity has a quality all its own. By collecting more high-quality samples, we allow our AI models to move beyond lucky guesses and converge towards a genuine, reliable understanding of the problem they are trying to solve.
