Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AI Toolkit: Calculus & Optimization
Lecture 24: Local Minima: The Traps and Valleys on the Learning Landscape
We’ve established our strategy for training an AI: use Gradient Descent to walk downhill on the cost function landscape until we reach the bottom of a valley. This seems straightforward, but it hides a subtle and classic problem in the world of optimization.
What if our landscape isn’t a simple, perfect bowl? What if it’s a rugged mountain range with countless valleys, some shallow and some incredibly deep?
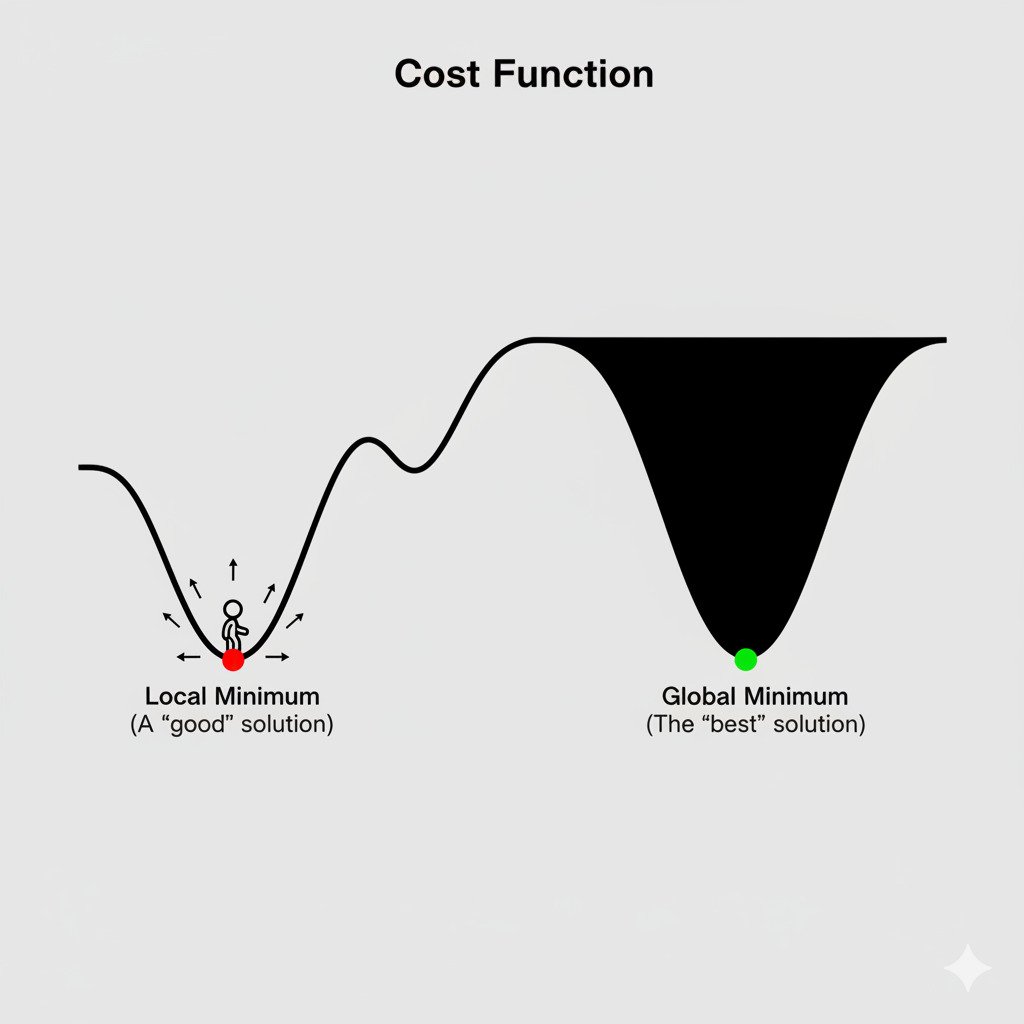
Global vs. Local Minima: Finding the True Bottom
In a complex error landscape, we can define two types of “bottoms”:
- Global Minimum: This is the absolute lowest point in the entire landscape. It represents the best possible set of parameters for our model, the lowest achievable error. This is the treasure we are ultimately searching for.
- Local Minimum: This is the bottom of a smaller, localized valley. It’s a point where, if you look at your immediate surroundings, you are at the lowest point. The ground goes up in every direction. However, there might be a much deeper valley on the other side of the mountain range.
The problem is that Gradient Descent is a “greedy” algorithm. It only ever looks at the immediate slope and takes the step that seems best right now. If it walks into a local minimum, the slope in all directions will be zero or positive. The gradient will become zero, and the algorithm will stop, thinking it has found the solution. It gets “stuck,” perfectly content in its small valley, unaware that a vast, deeper canyon—a much better solution—exists elsewhere in the landscape.
For decades, this was considered a major potential roadblock for training complex models. How could we ever be sure we hadn’t just gotten trapped in a mediocre local minimum?
The Surprising Reality of High Dimensions
While getting stuck in local minima is a real problem for low-dimensional optimization, a fascinating and counter-intuitive discovery was made as researchers began working with the massive, high-dimensional error landscapes of deep neural networks.
In a space with millions of dimensions (parameters), a true “bowl-shaped” local minimum—where the landscape curves up in every single one of the millions of directions—is statistically very, very rare.
Instead, what we find more often are saddle points.
- A saddle point is a point where the gradient is zero (it’s a flat spot), but it’s not a true minimum. It’s a minimum in some directions, but a maximum in others. Think of the shape of a horse’s saddle: if you’re in the center, you can go downhill by moving forward or backward (along the horse’s spine), but you’d have to go uphill to move left or right (up the sides of the saddle).
In high-dimensional space, it’s far more likely that a point with a zero gradient is a saddle point, not a true local minimum.
Why This Matters: Escaping the Traps
This changes everything. While Gradient Descent can slow down or struggle to navigate a flat region around a saddle point, it’s not permanently “trapped” in the same way it would be in a local minimum.
- The noisy, random steps of Stochastic Gradient Descent (SGD), which we discussed in the last lecture, are particularly good at escaping these saddle points. The “jiggle” provided by using a random mini-batch can be just enough to push the model off the flat area and into a downhill direction that it might have otherwise missed.
- Advanced optimization algorithms (like Adam or RMSprop) have built-in “momentum” that helps them “roll” through these flat saddle point regions instead of stopping.
Furthermore, research suggests that in very large neural networks, most of the local minima that do exist are of a similarly low error value. The difference in performance between getting stuck in “local minimum A” versus “local minimum B” is often negligible in practice. The real challenge has shifted from avoiding local minima to navigating the vast, complex terrain of saddle points efficiently.
So, while the classic problem of local minima is a crucial concept to understand, the modern view is that for the massive models we use today, it’s less of a show-stopping trap and more of a complex terrain to be navigated with clever, stochastic algorithms. The journey might be bumpy, but getting stuck forever is less of a concern than we once thought.
