Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AI Toolkit: Calculus & Optimization
Lecture 23: Stochastic Gradient Descent (SGD): Learning Faster with “Good Enough” Steps
In our last few lectures, we’ve built a solid understanding of Gradient Descent. The process is clear: calculate the gradient of the cost function, take a small step in the opposite direction, and repeat until we find the minimum error.
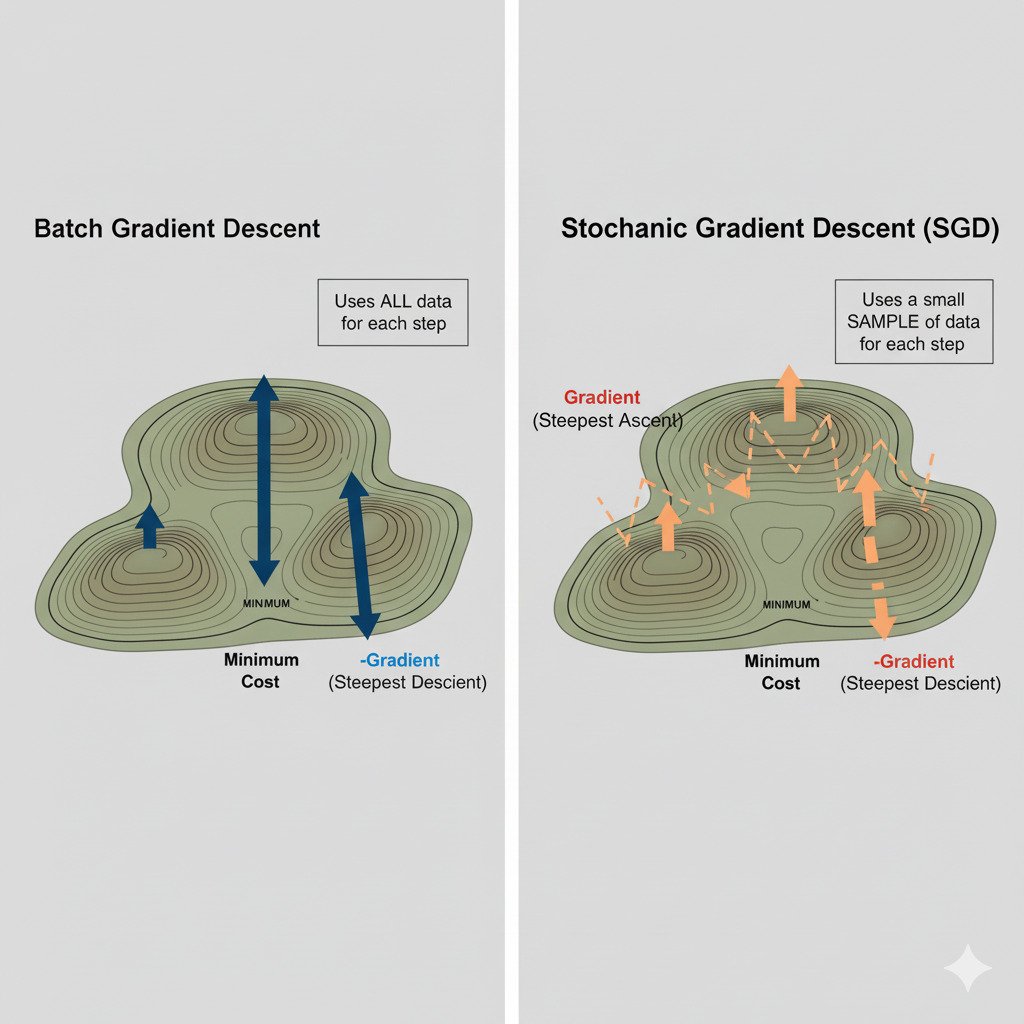
There’s just one problem. To calculate the true gradient, our cost function needs to be evaluated across every single data point in our entire training set. If you have a million images, that means processing a million images just to compute a single, perfect “downhill” direction and take one step! This is known as Batch Gradient Descent. It’s precise, but for the massive datasets used in modern AI, it’s agonizingly, impractically slow.
So, how do we train models on terabytes of data? We use a faster, more nimble, and slightly more chaotic approach called Stochastic Gradient Descent (SGD).
The SGD Strategy: Don’t Let Perfect Be the Enemy of Good
Imagine our “walking in the fog” analogy again. Batch Gradient Descent is like asking every person in a huge crowd (the entire dataset) for their opinion on which way is downhill, averaging all their answers to find the perfect direction, and then taking one step.
Stochastic Gradient Descent is like randomly grabbing just one person (or a small handful of people) from the crowd, asking their opinion, and immediately taking a step based on their “good enough” advice. Then you grab another random person and repeat.
- “Stochastic” simply means “random.” We are using a random sample of our data to guide our descent.
- “Mini-Batch”: In modern practice, we usually don’t use just one data point. We use a small, random sample called a “mini-batch” (e.g., 32, 64, or 256 data points). This is technically called “Mini-Batch Gradient Descent,” but the term SGD is often used to describe this general approach.
The “Noisy” but Efficient Path
The direction calculated from a small mini-batch won’t be the perfect downhill direction. It will be a slightly “noisy” or “drunken” approximation. The path the model takes down the error landscape won’t be a smooth, direct line. It will be a zig-zagging, stochastic walk.
So, why would we prefer this seemingly erratic path?
- Massive Speed Increase: The speed gain is astronomical. Instead of processing a million data points to take one step, we might process just 32. We can take thousands of these “good enough” steps in the same amount of time it would take to compute a single “perfect” step. The model starts improving much, much faster.
- Escaping Local Minima: The inherent noise in SGD can be a feature, not a bug! Imagine an error landscape with many valleys. A perfect, smooth descent (Batch GD) might get stuck in the first shallow valley it finds (a “local minimum”). The noisy, zig-zagging steps of SGD can sometimes give the model enough of a “jiggle” to bounce out of a shallow valley and continue its journey towards a much deeper, better valley (a “global minimum” or a better local minimum).
The Trade-Off: Speed vs. Precision
SGD introduces a trade-off. We sacrifice the precision of each individual step for a massive increase in the number of steps we can take. Over the long run, these thousands of slightly imperfect steps will average out and guide the model effectively towards the minimum.
It’s like navigating a city. Batch Gradient Descent is like using a highly detailed map to plan the perfect, optimal route before you even start walking. SGD is like asking a local for directions every 30 seconds. The second approach might involve a few wrong turns, but you’ll start moving immediately and likely get to your destination much faster, especially in a complex, unfamiliar city.
Almost every deep learning model you encounter today is trained using some variant of Stochastic Gradient Descent. It’s the pragmatic, efficient algorithm that makes learning on massive, real-world datasets not just possible, but practical.
