Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AIToolkit: Calculus & Optimization
Lecture 21: Gradient Descent: The Simple Algorithm for “Learning” by Taking Steps
We’ve arrived at a pivotal moment in our journey. Over the last five lectures, we’ve assembled all the necessary components:
- We have a Cost Function that defines a vast, hilly “error landscape,” quantifying how wrong our model is.
- We can find the Partial Derivative of this function for each of our model’s parameters.
- We can combine these into a Gradient vector, our compass that points in the direction of steepest ascent.
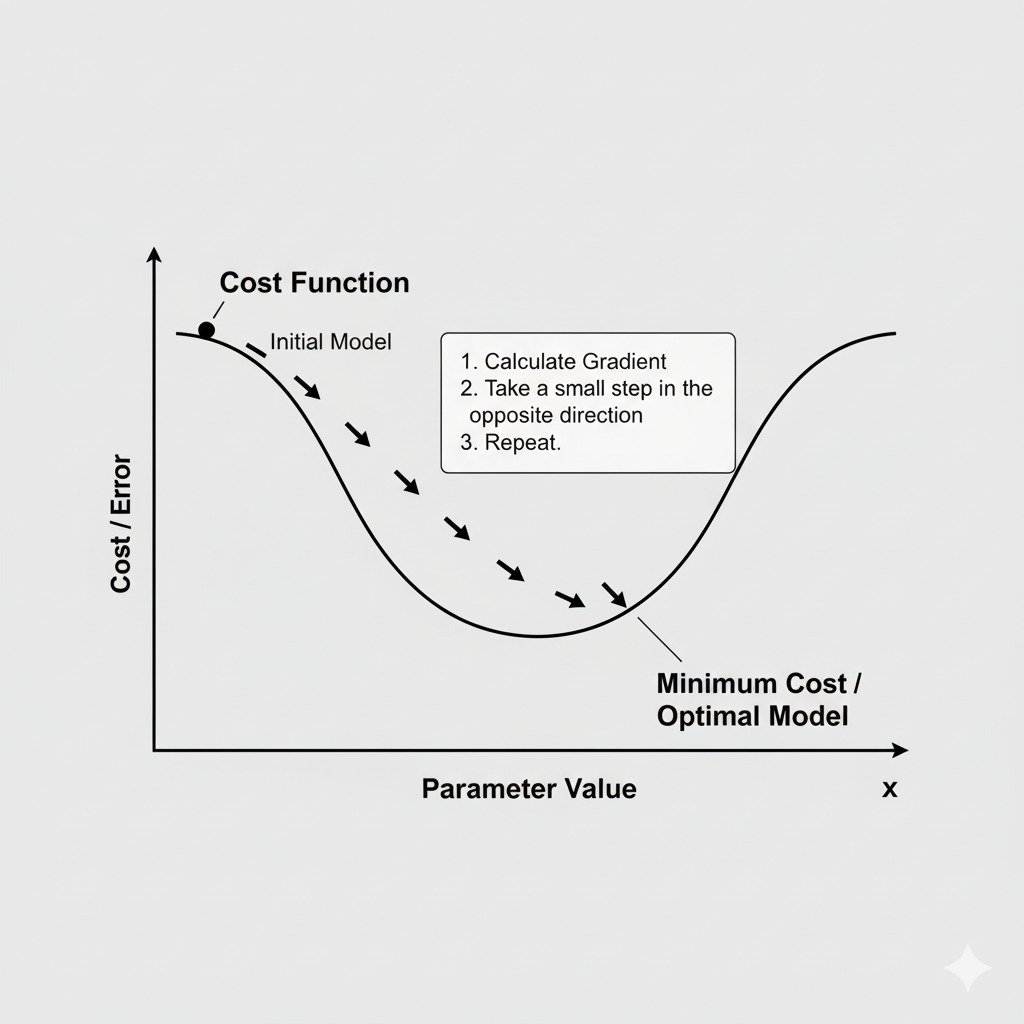
Now, we will put it all together. How does an AI model actually learn? It does so by using a simple, elegant, and profoundly powerful algorithm called Gradient Descent.
The Strategy: Walking Downhill in the Fog
Imagine you’re standing on the side of a giant, foggy mountain valley. Your goal is to reach the lowest possible point, but the fog is so thick you can only see the ground right under your feet. What’s your strategy?
It would probably be something like this:
- Feel the slope of the ground where you are.
- Identify which direction is the steepest way downhill.
- Take one small, careful step in that direction.
- Stop. Re-evaluate the new slope under your feet, and repeat the process.
Step by step, you would cautiously make your way down the mountainside, always choosing the most efficient path based on your immediate surroundings, until you eventually find yourself at the bottom of the valley where the ground is flat.
This is exactly what Gradient Descent does.
The Gradient Descent Algorithm
Let’s translate our analogy into the formal algorithm that trains our AI model. The “position” on the mountain is our model’s current set of parameters (weights). The “elevation” is the value of the Cost Function.
- Initialize: Start with a random set of weights for our model. This is like dropping our hiker at a random spot on the mountainside.
- Calculate the Gradient: At our current position (with our current weights), compute the gradient of the cost function. This vector, ∇E, tells us the direction of steepest ascent.
- Go the Opposite Way: To go downhill, we move in the direction of the negative gradient, -∇E.
- Take a Step (Update the Weights): We update every single weight in our model by taking a small step in this downhill direction. The formula for updating a single weight w looks like this:
new_weight = old_weight – (learning_rate * partial_derivative_for_w)- learning_rate: This is a small number that controls the size of our step. We’ll discuss this in the next lecture.
- partial_derivative_for_w: This is the slope for this specific weight, taken from the gradient vector.
- Repeat: Go back to Step 2 and repeat the process with the new, updated weights.
This loop—calculate gradient, update weights, repeat—is performed hundreds, thousands, or even millions of times. With each iteration, our model’s parameters are adjusted to take it one step closer to the bottom of the error valley. The “learning” is this iterative process of stepping downhill.
The “Aha!” Moment of Optimization
When you see an AI “training,” with progress bars and decreasing error metrics, what you are watching is the Gradient Descent algorithm in action. You’re watching the model take step after step down the slope of its own error function, guided by the compass of the gradient, until it converges on a set of parameters that produces the lowest possible error.
This simple concept—”take a small step in the direction of the negative gradient and repeat”—is arguably the most important algorithmic idea in modern machine learning. It’s the engine that drives the “learning” in everything from simple predictive models to the most massive deep neural networks. It transforms the abstract goal of minimizing a function into a concrete, iterative procedure that a computer can execute.
In our next and final lecture for this section, we’ll look at the one crucial detail we’ve glossed over: how do we choose the size of our step?
