Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AI Toolkit: Calculus & Optimization
Lecture 19: The Gradient: The “Steepest Path” to the Right Answer
In our last lecture, we learned how to manage the overwhelming complexity of an AI model’s error function using partial derivatives. By freezing all parameters but one, we could find the “slope” of our error landscape in the direction of each individual parameter.
We were left with a collection of thousands, or even millions, of individual slopes. Now, how do we combine this information into a single, actionable instruction? We do this by assembling them into one of the most important objects in all of optimization: the gradient.
What is the Gradient?
Simply put, the gradient of a function is a vector where each element is the partial derivative of that function with respect to one of its inputs.
If our error function E depends on a set of weights w₁, w₂, w₃, …, then the gradient of E, often denoted as ∇E (pronounced “nabla E”), is:
∇E = [ (∂E/∂w₁), (∂E/∂w₂), (∂E/∂w₃), … ]
Where ∂E/∂w₁ is the mathematical notation for “the partial derivative of the Error with respect to w₁.”
So, the gradient is just a neat package—a vector that contains all the slope information for every possible direction (every parameter) in our high-dimensional error landscape.
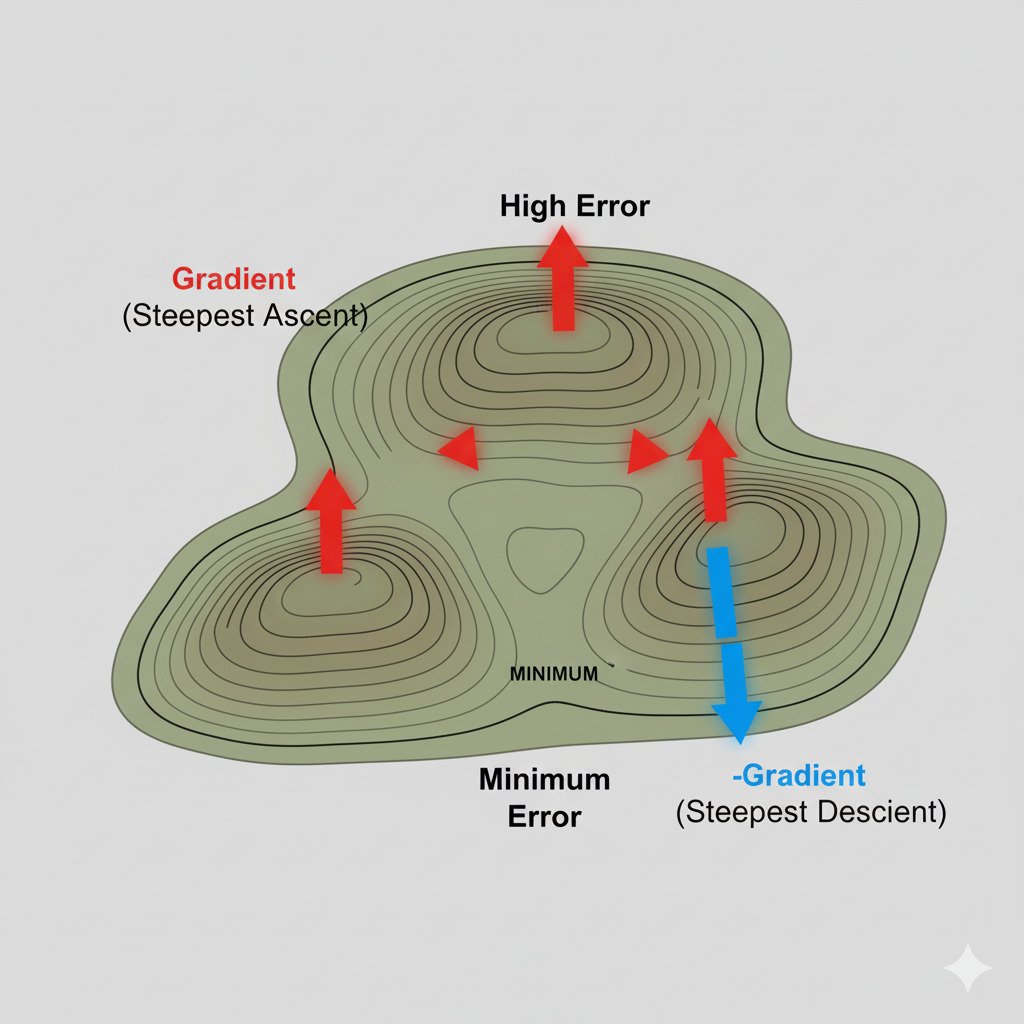
The Gradient as a Compass for Steepest Ascent
Why is this vector so special? Because the gradient vector has a magical property: it always points in the direction of the steepest possible ascent at that point in the landscape.
Imagine you are standing on a foggy mountainside (our error landscape) and you want to climb uphill as quickly as possible. You check the slope in every direction around you. The gradient is the compass needle that instantly points you up the most vertical path from your current position.
- The direction of the gradient vector tells you the path of steepest increase.
- The magnitude (or length) of the gradient vector tells you how steep that path is. A long gradient vector means you’re on very steep ground, while a short one means you’re on a gentle slope.
The Key to Optimization: Go the Other Way!
Our goal in training an AI is not to climb the hill of error, but to get to the bottom of the valley. We want to minimize the error.
So, if the gradient vector ∇E points in the direction of the steepest ascent, what is the direction of the steepest descent?
It’s simply the opposite direction of the gradient: -∇E.
This gives us our grand, unified instruction for improving our AI model. At any given point in the training process:
- Calculate the gradient of the error function.
- Take a small step in the opposite direction of the gradient.
This process, called Gradient Descent, is the algorithm that powers the training of virtually all modern neural networks. It’s an iterative process of finding the steepest path downhill and taking a step, over and over again.
Visualizing Gradient Descent
Imagine a ball being placed on our hilly error landscape.
- Gravity pulls the ball in the direction of steepest descent (opposite the gradient).
- The ball rolls a short distance in that direction.
- It stops, re-evaluates the new steepest path from its new position, and rolls again.
- It continues this process, taking successive steps downhill, until it settles at the bottom of the nearest valley.
This is exactly what our AI model does. The “ball” is our set of model parameters. Each “step” is an update to those parameters, guided by the negative gradient.
The gradient is the ultimate compass for optimization. It transforms the monumental task of searching a million-dimensional space for a minimum into a simple, repeatable instruction: “Find the steepest way up, and take a step the other way.”
In our next lecture, we’ll formalize this process and introduce the final crucial piece of the puzzle: the “learning rate,” which determines how big of a step we take.
