Series: The Sequentia Lectures: Unlocking the Math of AI
Part 7: The Frontier – Open Problems & Research Directions
Lecture 59: Explainability & Interpretability (XAI): Can We Understand Why an AI Made a Decision?
Throughout this lecture series, we have built a powerful understanding of how to construct and train complex AI models. We can feed data into a deep neural network, and through the magic of backpropagation and gradient descent, it learns to make remarkably accurate predictions.
But this success has created a new, profound challenge. We have a model that works, but we often have no idea why. The very complexity that gives deep learning its power—millions of parameters interacting in non-linear ways—turns the model into an opaque “black box.”
This is the central problem tackled by the crucial and rapidly growing research field of Explainable AI (XAI).
The “Black Box” Problem
Imagine a cutting-edge AI model used in a hospital to predict whether a patient is at high risk for a certain disease.
- Input: The patient’s entire medical record (lab results, scans, history).
- Output: A prediction: “High Risk.”
A doctor receives this prediction. Their immediate, and correct, next question is: “Why?”
- Was it because of the patient’s cholesterol levels?
- Was it a subtle pattern in the X-ray that a human might miss?
- Or did the model accidentally learn a spurious correlation, like the fact that the patient was treated on a Tuesday?
Without an answer to “why,” it’s incredibly difficult to trust the model’s prediction, especially in high-stakes domains like medicine, finance, and justice. A model that is 99% accurate but makes its 1% of mistakes for nonsensical reasons can be dangerous.
Interpretability vs. Explainability
In XAI, two related goals are often discussed:
- Interpretability: This refers to models that are inherently simple enough for a human to understand their entire decision-making process. A small Decision Tree (from Lecture 45) is highly interpretable; you can print out the flowchart and follow every step. A simple Linear Regression model is also interpretable; you can look at the learned weights and see exactly how much each feature contributes to the final prediction.
- Explainability: This refers to the techniques we can apply to a complex, non-interpretable “black box” model (like a deep neural network) to get an post-hoc (after the fact) explanation for a specific prediction. The model itself remains a black box, but we can probe it to understand its behavior.
Much of the research in XAI is focused on explainability, as our most powerful models are often the least interpretable.
Peering Inside the Black Box: XAI Techniques
How can we mathematically generate an explanation? Many techniques are based on asking “what if?” questions and leveraging the calculus we’ve already learned.
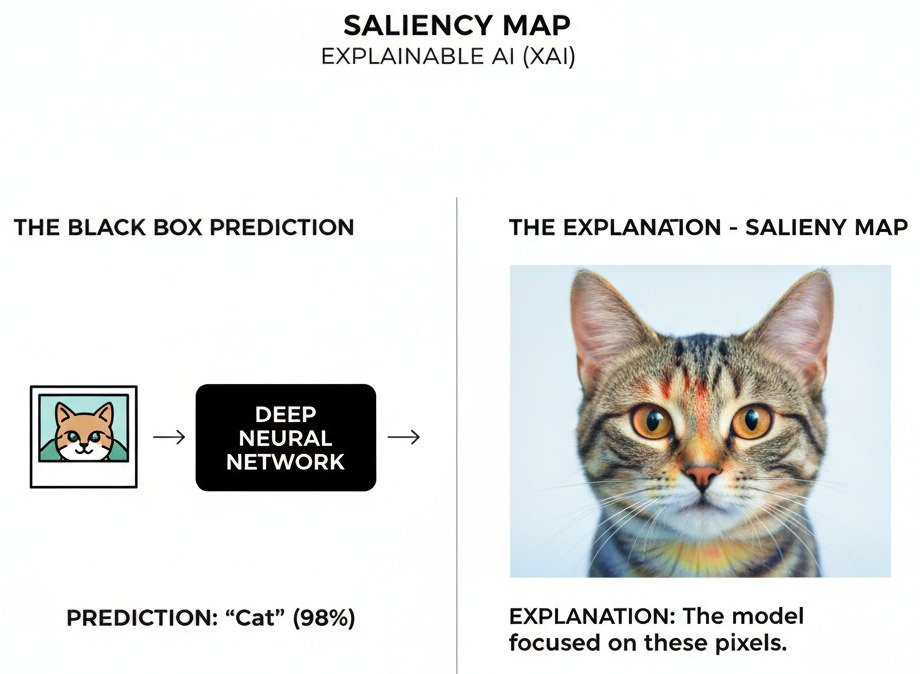
- Saliency Maps / Feature Attribution: This is a common technique for image models. To understand why a CNN classified an image as a “cat,” we can use methods that are related to backpropagation. We calculate the gradient of the final “cat” output with respect to the input pixels.
- The Intuition: Pixels with a large gradient are the ones that, if changed slightly, would have the biggest impact on the “cat” score. These are the pixels the model is “paying attention” to.
- The Result: We can generate a “heat map” (a saliency map) that highlights the most influential pixels. In a good model, this map will highlight the cat’s ears, whiskers, and eyes. If it highlights a patch of grass in the corner, we know our model has learned a spurious correlation.
- LIME (Local Interpretable Model-agnostic Explanations): LIME is a clever technique that works on any model. To explain a single prediction, it generates a new, simple dataset of points around that specific data point. It then trains a simple, interpretable model (like a linear regression or a small decision tree) that only has to be accurate in that small, local neighborhood. The explanation for the simple model then serves as an approximation for the complex model’s behavior at that specific point.
- SHAP (SHapley Additive exPlanations): Based on concepts from cooperative game theory, SHAP values provide a sophisticated way to fairly distribute the “credit” for a prediction among all the input features, telling us how much each feature contributed to pushing the prediction away from the baseline.
The Frontier: From Correlation to Causal Reasoning
XAI is one of the most active and important frontiers in AI research. It represents a push to move our models beyond simply being powerful correlation-finding machines. The goal is to build systems that can provide plausible, human-understandable justifications for their decisions.
This is not just about debugging or building trust. It’s about ensuring fairness, identifying hidden biases in our data, and ultimately, building AI systems that can reason and collaborate with us in a more transparent and meaningful way. The quest for explainability is the quest to turn the “black box” into a glass one.
