Series: The Sequent-ia Lectures: Unlocking the Math of AI
Part 6: Advanced Architectures & Concepts
Lecture 51: LSTMs & GRUs: The “Gates” That Give RNNs a Better Memory
In our last lecture, we discovered the Achilles’ heel of simple Recurrent Neural Networks (RNNs): the vanishing gradient problem. Their inability to maintain a memory over long sequences made them impractical for many real-world tasks. The solution? A more sophisticated and ingenious recurrent unit with built-in mechanisms for memory management.
Meet the Long Short-Term Memory (LSTM) and its slightly simpler cousin, the Gated Recurrent Unit (GRU).
The Problem with Simple RNNs: A Single, Jumbled Memory Stream
A simple RNN takes its previous memory (the hidden state), combines it with the new input, and mashes them together to form the new memory. Every piece of information is treated the same way, passed through the same transformation at every step. This makes it impossible for the network to distinguish between crucial long-term context and irrelevant short-term details. It’s like trying to remember a key plot point from the first chapter of a book while simultaneously trying to remember every single “the” and “a” along the way.
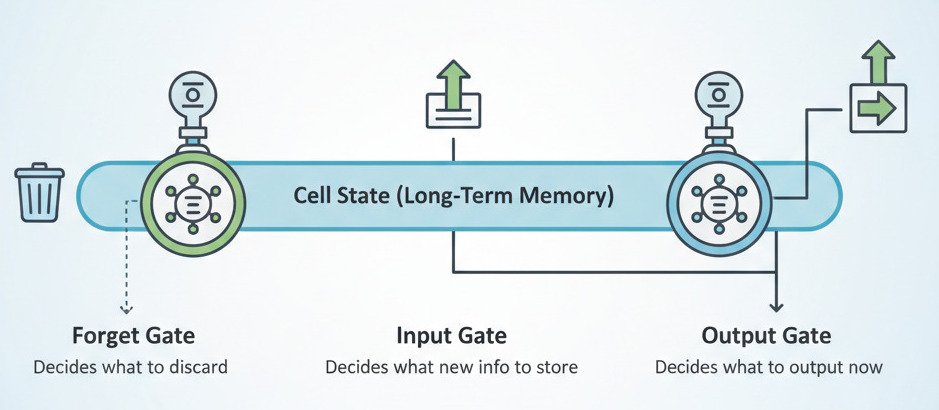
The LSTM Solution: A Separate “Memory Lane” with Gates
The LSTM architecture, introduced by Sepp Hochreiter and Jürgen Schmidhuber, solves this with a brilliant design. It introduces a separate “conveyor belt” of information called the cell state. This cell state runs straight down the entire sequence, with the ability to carry long-term memories with minimal distortion.
The key innovation is a set of gates—neural network layers with sigmoid activations—that act as regulators for this memory lane. They learn to control what information is added, removed, or read from the cell state.
There are three main gates:
- The Forget Gate: This gate looks at the new input and the previous hidden state and decides what information from the old cell state is no longer relevant and should be “forgotten.”
- Intuition: If the network sees a new subject in a sentence (e.g., “John went to the store. Mary…”), the forget gate might learn to erase the information about “John” being the subject.
- The Input Gate: This gate decides which new information from the current input is important enough to be stored in the cell state. It works in two parts: it identifies potentially useful information and then decides how much of it to actually add.
- Intuition: When it sees the new subject “Mary,” the input gate decides that this is important new context and should be added to the memory.
- The Output Gate: This gate takes the updated cell state (which now contains the long-term memory) and combines it with the current input to decide what the output for this specific time step should be. It filters the memory to produce a relevant, context-aware output.
- Intuition: If the rest of the sentence is “…bought her favorite snack,” the output gate uses the memory of “Mary” to correctly influence the choice of the pronoun “her.”
The GRU: A Simpler, Gated Cousin
The Gated Recurrent Unit (GRU) is a more recent and slightly simpler alternative to the LSTM. It also uses gates to manage memory but combines the “forget” and “input” gates into a single “update gate”. It also merges the cell state and hidden state.
While it has fewer parameters and can be slightly faster to train, the core concept is the same: use learnable gates to dynamically control the flow of information and memory. In practice, the performance of LSTMs and GRUs is often comparable, and the choice between them can depend on the specific dataset and task.
Why Gates Solve the Vanishing Gradient Problem
The “gating” mechanism is what allows these networks to overcome the vanishing gradient problem. The cell state’s “conveyor belt” design, with its explicit “add” and “forget” operations, creates a much more direct path for the gradient to flow through time.
The network can learn to keep the forget gate “open” (close to 1) for important information, allowing that information (and its gradient) to pass through many time steps without shrinking. It effectively learns to create “shortcuts” for the error signal, ensuring that events from the distant past can still influence the weight updates.
By giving the network the ability to explicitly control its own memory—to remember, to forget, and to output—LSTMs and GRUs revolutionized what was possible with sequential data. They are the foundational architectures that powered the boom in natural language processing, from early machine translation and sentiment analysis to the sophisticated language models we see today.
