Series: The Sequentia Lectures: Unlocking the Math of AI
Part 5: Core Machine Learning in Action
Lecture 45: Decision Trees & Random Forests: Making Predictions with Flowcharts
So far, our journey into AI models has been dominated by neurons, weights, and gradients—models that learn smooth mathematical functions. But not all successful AI models think this way. Some make predictions by following a simple, intuitive structure that we all use every day: a flowchart.
This is the world of Decision Trees and their powerful evolution, Random Forests.
Decision Trees: A Game of “20 Questions”
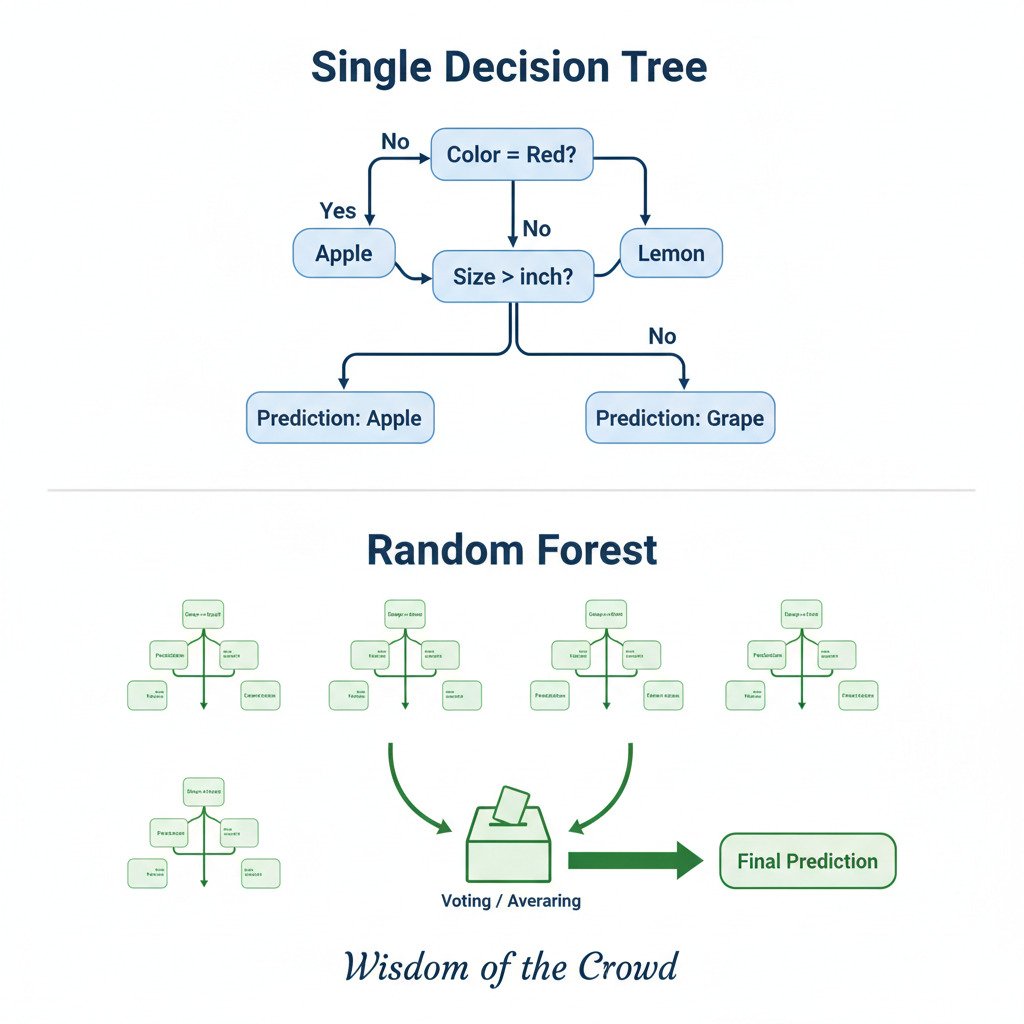
A Decision Tree is a model that makes predictions by asking a series of sequential “yes/no” questions about the features of a data point. It’s like playing a game of “20 Questions” to arrive at a conclusion.
The structure is simple and tree-like:
- Root Node: The first question that splits the entire dataset.
- Internal Nodes: Subsequent questions that split the data into smaller, more refined groups.
- Branches: The paths representing the “yes” or “no” answers to the questions.
- Leaf Nodes: The final endpoints of the tree, which provide the final prediction or classification.
An Intuitive Example: Predicting Fruit
Imagine a model trying to classify a piece of fruit as an “Apple,” “Grape,” or “Lemon.” A decision tree might learn a set of rules like this:
- Root Node Question: Is the color == ‘red’?
- Yes: Follow the “yes” branch. The prediction is likely Apple. (Leaf Node)
- No: Follow the “no” branch to the next question.
- Internal Node Question: Is the diameter > 1 inch?
- Yes: It’s not red and it’s large. The prediction is likely Lemon. (Leaf Node)
- No: It’s not red and it’s small. The prediction is likely Grape. (Leaf Node)
The “learning” process for a decision tree involves finding the best possible sequence of questions (and the best split points, like diameter > 1 inch) that most effectively partitions the training data into pure, well-defined groups. The model seeks the questions that provide the most “information gain” at each step.
The Weakness of a Single Tree: Overfitting
Decision trees are incredibly easy to understand and interpret. You can literally print out the flowchart and see exactly how the model is making its decisions.
However, a single, deep decision tree has a major weakness: it is highly prone to overfitting. A deep tree can keep asking questions until it has created a specific path for every single data point in the training set. It memorizes the training data perfectly but fails to generalize to new, unseen data, just like our “memorizing student” from Lecture 42.
Random Forests: The Wisdom of the Crowd
So, how do we get the interpretability and power of decision trees without their tendency to overfit? We use an ingenious technique called an ensemble method. We don’t just build one tree; we build a whole forest!
A Random Forest is an “ensemble” model that combines hundreds or thousands of slightly different decision trees to make a final prediction.
Here’s how it works:
- Bootstrap Sampling: To build each tree, the algorithm takes a random sample of the training data (with replacement). This means each tree sees a slightly different version of the data.
- Random Feature Selection: At each node in each tree, when deciding on the best question to ask, the algorithm is only allowed to consider a random subset of the available features.
- Build Many Diverse Trees: By repeating these two steps, we build a “forest” of many deep, complex trees. Each individual tree is likely overfit to its own little sample of the data, but they are all overfit in different ways because they’ve seen different data and considered different features.
- Vote for the Final Prediction: To make a prediction for a new data point, we run it through every tree in the forest. Each tree gets one “vote” for the final classification. The class that receives the most votes is the final prediction of the Random Forest.
This is the “wisdom of the crowd” in action. While each individual tree might be a flawed, biased expert, their collective, averaged vote cancels out the individual errors and results in a final prediction that is remarkably accurate, stable, and resistant to overfitting.
Random Forests are one of the most powerful and widely used “off-the-shelf” machine learning algorithms. They are robust, handle complex datasets well, and provide a beautiful example of how combining many simple (and even flawed) models can lead to a result that is far greater than the sum of its parts.
