Series: The Sequentia Lectures: Unlocking the Math of AI
Part 5: Core Machine Learning in Action
Lecture 44: Support Vector Machines (SVMs): Finding the “Widest Road” Between Data
In our journey so far, we’ve learned about Logistic Regression, which finds a line to separate two classes of data. But is any separating line as good as another? Imagine a scatter plot with two distinct clusters of points. You could draw infinitely many lines that perfectly separate them. Which one is the best?
This is the question that Support Vector Machines (SVMs) were designed to answer. Before the recent dominance of deep learning, SVMs were a powerful and go-to algorithm for classification tasks. Their elegance lies in a simple, powerful geometric intuition: don’t just find a line that separates the classes, find the line that creates the widest possible road between them.
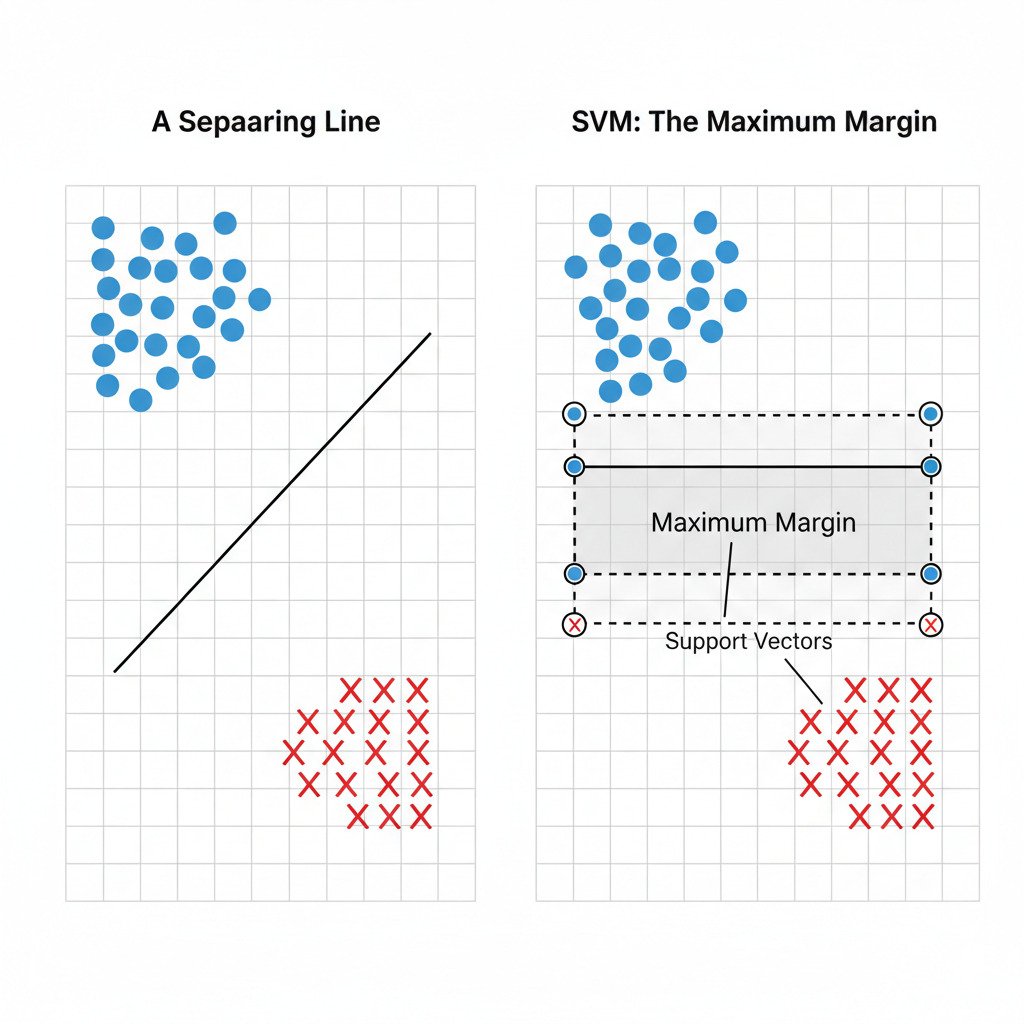
The Maximum Margin Classifier
An SVM is a maximum margin classifier. Instead of just finding a decision boundary, it tries to maximize the margin—the empty space or “street” between the two classes. The decision boundary is then the line running down the exact middle of this street.
Why is a wider margin better? Because it’s more robust. A line that is very close to the data points of one class is more likely to misclassify new, unseen data points that might fall on the “wrong” side of the line due to slight noise or variation. A line with a large margin is less sensitive to these small variations, making it better at generalizing.
The “Support Vectors”: The Critical Data Points
So, how does the SVM find this widest possible road? Interestingly, the exact placement of this road is determined by only a handful of data points—the ones that are closest to the opposing class. These are the “edge cases,” the points that lie right on the edge of the margin.
These crucial data points are called the support vectors.
- They are the only points that “support” the final placement of the decision boundary.
- If you were to move any of the other data points (the ones far from the boundary), the optimal line would not change at all! The SVM is completely insensitive to them.
- But if you move just one of the support vectors, the optimal line will shift.
This makes SVMs computationally efficient and highlights their focus on the most difficult-to-classify points that truly define the boundary between classes.
Handling Non-Linear Data: The Kernel Trick
This all works beautifully for data that can be separated by a straight line (“linearly separable”). But what if our data looks like a circle of one class inside another? No straight line can separate them.
This is where the SVM’s most famous and ingenious feature comes in: the kernel trick.
The kernel trick is a mathematically clever way of dealing with non-linear data without doing complex calculations. Here’s the intuition:
- Project to a Higher Dimension: Imagine our 2D data (the circle within a circle) is a drawing on a flat sheet of rubber. What if we could project this data into a higher dimension? Imagine pushing up on the center of the rubber sheet, creating a 3D “hill.”
- Find a Simple Separator: In this new, higher-dimensional space, the data that was inseparable in 2D might now be easily separable by a simple, flat plane! The red points are now at the top of the hill, and the blue points are at the bottom.
- Project Back Down: We can then project this separating plane back down to our original 2D space, where it will look like a complex, non-linear curve (a circle in this case).
The “trick” of the kernel is that it allows the SVM to calculate the relationships between data points in this high-dimensional space without ever actually having to compute the new coordinates. It’s a highly efficient mathematical shortcut that gives SVMs the power to learn incredibly complex, non-linear decision boundaries.
Conclusion
Support Vector Machines offer a unique and powerful geometric perspective on classification. By focusing on maximizing the margin between classes, they create robust and often highly accurate models. While deep learning has become more dominant for unstructured data like images and text, SVMs remain a powerful and relevant tool, especially for structured datasets where a clear margin of separation is desirable. They are a beautiful example of how elegant geometric principles can be used to solve complex machine learning problems.
