Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AI Toolkit: Calculus & Optimization
Lecture 25: Beyond the Gradient: A Glimpse at More Advanced Optimizers (Adam, RMSprop)
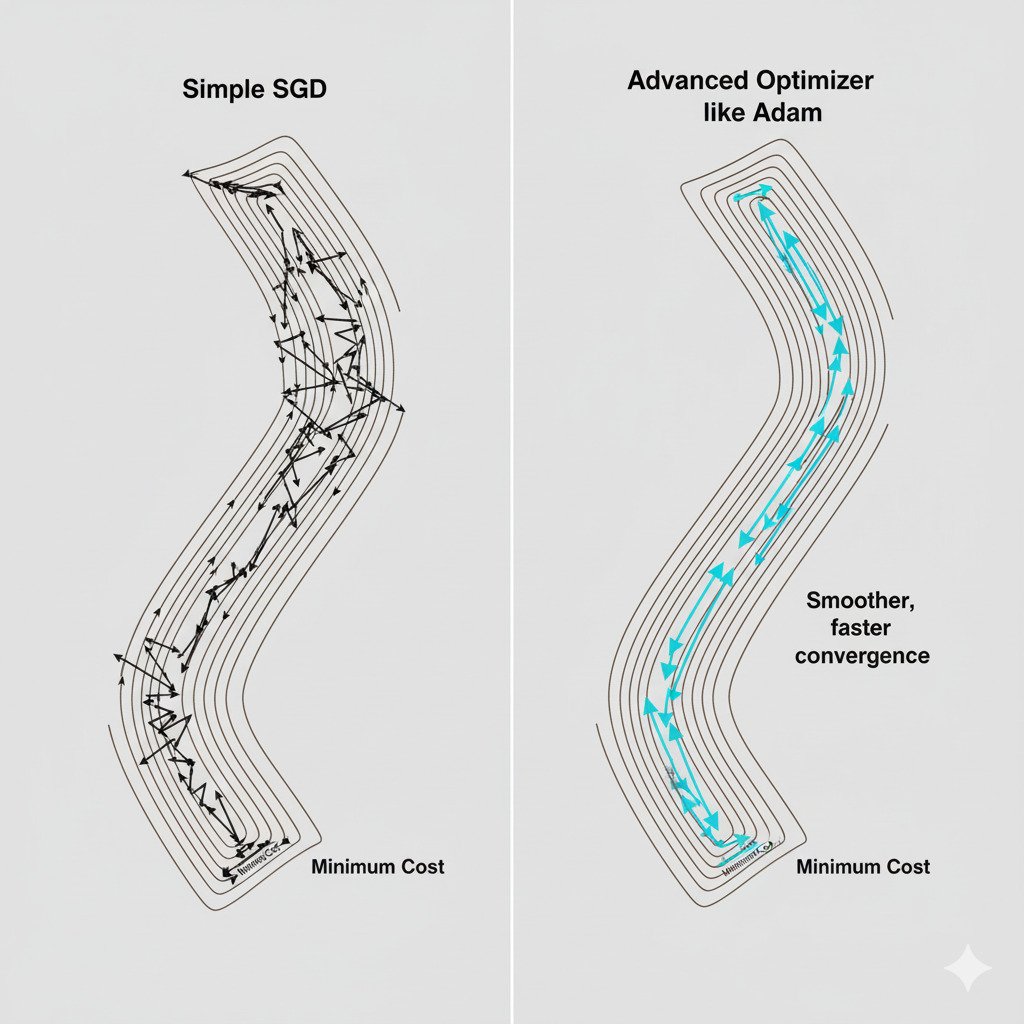
Over the past several lectures, we’ve built a powerful mental model for how AI learns. We have a cost function landscape, and we use Stochastic Gradient Descent (SGD) to take iterative steps “downhill” toward the minimum error. We even learned that the size of our steps, the learning rate, is a critical parameter.
But what if we could be smarter about our journey? What if, instead of taking the same-sized step for every parameter, we could adapt our strategy based on the terrain? This is the core idea behind the more advanced optimization algorithms that power virtually all modern deep learning.
Today, let’s take a brief, intuitive glimpse at two of the most popular: RMSprop and Adam.
The Problem with a Single Learning Rate
Plain SGD uses a single, fixed learning rate for every parameter in the model. But our error landscape is not uniform.
- In some directions (for some parameters), the valley might be extremely steep and narrow. A large learning rate here would cause us to overshoot and bounce erratically.
- In other directions, the landscape might be a long, gentle, almost flat plain. A small learning rate here would lead to painfully slow progress.
It’s like trying to navigate a complex mountain range with your legs locked into a single stride length. It’s simply not efficient.
The Core Idea: Adaptive Learning Rates
Advanced optimizers work on the principle of adaptive learning rates. They maintain a separate, adaptable learning rate for each individual parameter in the model. They are like a smart hiker who can dynamically adjust their stride: taking small, careful steps on steep, treacherous terrain, and taking long, confident strides on flat, open ground.
Introducing Momentum: The Rolling Ball
One of the first improvements on SGD was the idea of momentum. Instead of just looking at the current gradient (the slope right now), the momentum optimizer also considers the direction it was moving in the previous steps.
Imagine a ball rolling down our error landscape. It builds up momentum.
- When rolling down a long, gentle slope, its speed increases, helping it travel faster.
- When it hits a small bump or a flat area (like a saddle point), its momentum helps it “roll” right over it instead of getting stuck.
- It also helps to smooth out the noisy, zig-zagging path of SGD into a more direct route.
RMSprop: Taming the Steep Valleys
RMSprop (Root Mean Square Propagation) is an optimizer that focuses on adapting the learning rate based on the recent history of the gradients.
- The Intuition: If a parameter’s gradient is consistently large and fluctuating (indicating a very steep, bouncy direction), RMSprop will decrease the learning rate for that specific parameter to prevent overshooting. If a parameter’s gradient is small and consistent (a gentle slope), it will keep the learning rate steadier, allowing for continued progress.
- The Effect: It’s excellent at dampening the oscillations in steep directions, allowing the model to make more direct progress toward the minimum.
Adam: The Best of Both Worlds
The Adam (Adaptive Moment Estimation) optimizer is arguably the most popular and widely used optimizer in deep learning today. Why? Because it combines the best of both worlds:
- It incorporates the idea of momentum (like a rolling ball, tracking the average of past gradients).
- It incorporates the adaptive learning rate mechanism of RMSprop (tracking the average of past squared gradients to scale the learning rate).
By combining these two powerful ideas, Adam is able to navigate complex, high-dimensional error landscapes with remarkable efficiency and stability. It’s a robust, all-purpose optimizer that often works well “out of the box” with its default settings, which is why it has become the go-to choice for so many data scientists and researchers.
Conclusion: The Smart Hiker
While the foundational concept of Gradient Descent—taking steps downhill—remains the core of AI training, the evolution from simple SGD to adaptive optimizers like Adam represents a huge leap in practical efficiency.
Think of it this way:
- Gradient Descent gives us the compass (the gradient).
- Stochastic Gradient Descent (SGD) tells us to check the compass frequently with a small sample.
- Adam and RMSprop give us the skills of an expert hiker, allowing us to use that compass to intelligently lengthen or shorten our stride based on the terrain, and to use our momentum to cruise through flat sections.
This concludes Part 3 of our series! We’ve journeyed from the basics of calculus to the sophisticated algorithms that drive modern AI optimization. With a solid grasp of Linear Algebra and Calculus, we are now fully prepared for Part 4, where we will finally build and train our first predictive model, Linear Regression, from scratch!
