Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AI Toolkit: Calculus & Optimization
Lecture 17: The Chain Rule: The Engine of Learning in Neural Networks
In our last lecture, we discovered the power of the derivative. It acts as a compass, telling us how a tiny change in a model’s parameter affects its final error, and thus which way to adjust that parameter to get better.
This works perfectly for a simple, one-step model. But what about a deep neural network, which is a long chain of interconnected layers? The output of Layer 1 affects Layer 2, which affects Layer 3, and so on, until we get to the final output and calculate the error.
How do we figure out how a parameter in the very first layer contributes to the final error at the very end of this long chain? The answer lies in one of the most elegant and important concepts in calculus: the Chain Rule.
The Chain Rule: A Cascade of Influence
Let’s forget math for a second and use a simple analogy. Imagine a line of three dominoes: A, B, and C.
- Nudging domino A causes domino B to fall.
- Domino B falling causes domino C to fall.
The Chain Rule is the mathematical principle that allows us to precisely calculate the overall effect of our initial nudge on the final outcome. It lets us answer the question: “How much does a tiny nudge on A affect the final state of C?”
We can figure this out by multiplying the individual rates of change:
(How much C changes for a change in B) * (How much B changes for a change in A)
This “chain” of multiplications gives us the total derivative of C with respect to A.
From Dominoes to Neural Networks
A deep neural network is just like this chain of dominoes, but instead of “falling,” we’re talking about mathematical functions.
Let’s imagine a simple 3-layer network:
- Input (x) is fed into Layer 1.
- The output of Layer 1 is fed into Layer 2.
- The output of Layer 2 is fed into the Final Output (y), which is then compared to the correct answer to get the Error (E).
We want to update a parameter (a “weight,” let’s call it w) in the very first layer. To do this, we need to know how a tiny change in w affects the final Error. This is the derivative of E with respect to w.
The Chain Rule allows us to calculate this by working backwards from the error:
- First, we calculate how the Error changes with respect to the Final Output. (Easy, it’s the last step).
- Then, we calculate how the Final Output changes with respect to the output of Layer 2.
- Then, we calculate how the output of Layer 2 changes with respect to the output of Layer 1.
- Finally, we calculate how the output of Layer 1 changes with respect to our weight, w.
By multiplying these individual derivatives together—chaining them—we get the overall derivative we were looking for: the precise influence of that single weight in Layer 1 on the total error at the end.
(dE/d_output) * (d_output/d_layer2) * (d_layer2/d_layer1) * (d_layer1/dw)
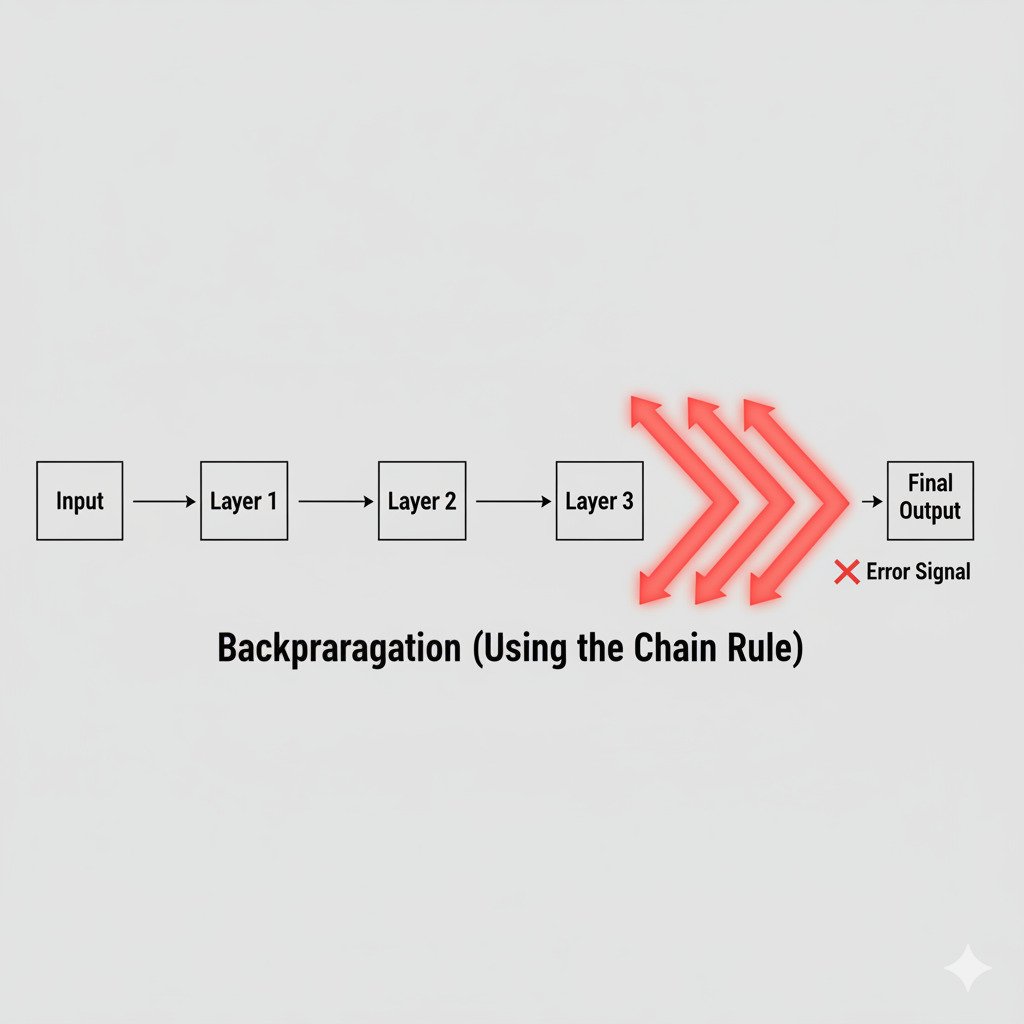
Backpropagation: The Chain Rule in Action
This process of starting at the final error and using the Chain Rule to work backwards through every layer of the network to calculate the derivatives for every single parameter is called Backpropagation.
It is, without exaggeration, the engine of modern deep learning.
Backpropagation is the algorithm that allows us to efficiently train deep, complex neural networks. It’s a systematic application of the Chain Rule that tells every single weight and parameter in the entire network—whether it’s in the first layer or the last—exactly how it should be adjusted to help reduce the final error.
Just like in our domino analogy, it allows the “effect” of the final domino falling (the error) to be traced all the way back to the initial nudge (the adjustment of a single parameter).
The Chain Rule, therefore, is not just an abstract concept from a calculus textbook. It’s the fundamental mechanism that enables deep learning, allowing an error signal to propagate backwards through a complex network and guide it, layer by layer, towards a more accurate solution.
