Series: The Sequentia Lectures: Unlocking the Math of AI
Part 3: The AI Toolkit: Calculus & Optimization
Lecture 16: What is a Derivative? Finding the Slope of Our Problem
Welcome to Part 3 of the Sequentia Lectures! In our previous parts, we learned to see data as points (vectors) in a vast landscape and AI models as functions (y = f(x)) that draw patterns through this landscape. But this raises the most important question in all of machine learning: if our model makes a mistake, how do we fix it? How do we know which way to adjust our function to make it better?
To answer this, we need a new tool, the cornerstone of calculus: the derivative.
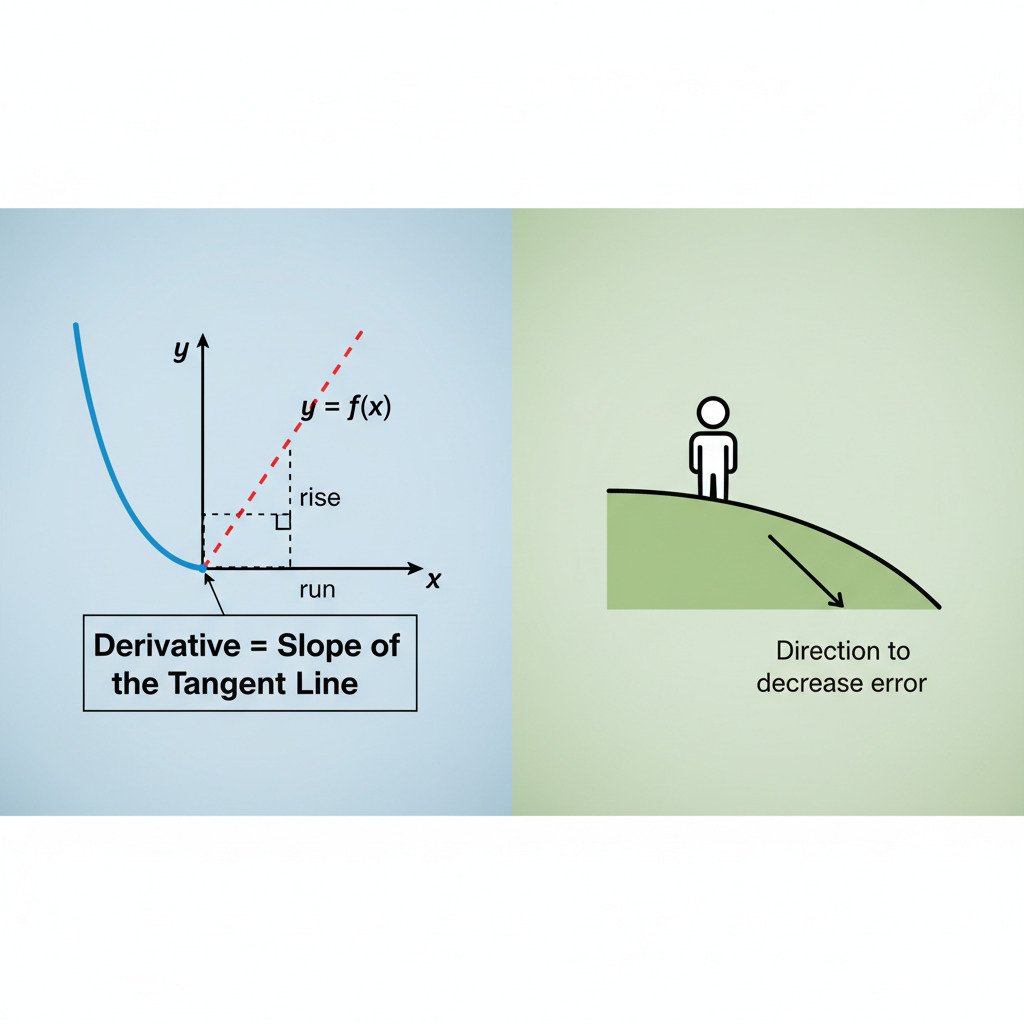
The Derivative as a Slope
Forget complex formulas for a moment. At its heart, the derivative of a function at a specific point is simply the slope of the line that is tangent to the function at that point. It tells us two things:
- Direction: Is the function increasing (positive slope), decreasing (negative slope), or flat (zero slope)?
- Magnitude: How steeply is it increasing or decreasing?
Imagine you are standing on a curvy hillside represented by a function. The derivative at your exact location tells you the steepness of the ground right under your feet. A large positive derivative means you’re on a steep upward climb. A small negative derivative means you’re on a gentle downward slope. A zero derivative means you’re at the very bottom of a valley or the very top of a hill.
From Hillsides to Error Functions
This is a nice physical analogy, but how does it apply to AI?
In machine learning, we don’t just have a function for our model’s predictions; we also have a “loss” or “error” function. This function measures how “wrong” our model is. It takes our model’s parameters (the numbers that define its recipe) as input and outputs a single number: the total error.
- High Error: Our model is making bad predictions.
- Low Error: Our model is doing well.
- Zero Error: Our model is perfect (rarely achievable).
The graph of this error function isn’t just a simple 2D curve; it’s a vast, high-dimensional “error landscape” with hills, valleys, and plains. The goal of “training” an AI is to find the lowest possible point in this landscape—the point of minimum error.
The Derivative as a Guide
This is where the derivative becomes our guide. Imagine our model is at a random point in this error landscape. It’s making mistakes, so its error is high. We want to take a step towards a lower point, but which way should we go?
We calculate the derivative of the error function with respect to one of our model’s parameters (e.g., a “weight” from our dot product lecture).
- If the derivative is positive: It means that increasing this parameter will increase the error. The slope is going uphill. To reduce the error, we need to go in the opposite direction—we should decrease the parameter.
- If the derivative is negative: It means that increasing this parameter will decrease the error. The slope is going downhill. To reduce the error, we should increase the parameter.
- If the derivative is zero: We are at a flat spot, potentially the bottom of a valley (the minimum error we’ve been searching for!).
The derivative gives us a precise, mathematical instruction for every single parameter in our model: “To reduce the overall error, adjust this specific parameter slightly up (or down).” It tells us the direction of steepest descent—the quickest way down the hill.
The Engine of Improvement
The derivative is the engine of optimization in AI. The process of training a neural network is a beautiful, iterative loop:
- Make a prediction.
- Calculate the error.
- Calculate the derivative of the error with respect to every single parameter in the model (this is a process called backpropagation, which we’ll touch on later).
- Use these derivatives to update each parameter slightly in the direction that will lower the error.
- Repeat millions of times.
With each repetition, the model takes a tiny step “downhill” in the error landscape, guided by the derivative, until it settles into a valley of low error.
The derivative, therefore, transforms the vague goal of “getting better” into a series of concrete, mathematical steps. It’s the compass that allows our AI to navigate the complex landscape of its own mistakes and find its way toward a better solution.
